Serverless is more than AWS Lambda

Too often serverless is equated with just AWS Lambda.
Yes, it's true: Amazon Web Services (AWS) helped to pioneer what is commonly referred to as serverless today with AWS Lambda, which was first announced back in 2015.
But in 2020, it's important for enterprises to understand that the serverless landscape is much bigger with more opportunities.
Serverless is sometimes (narrowly) defined as just being about functions-as-a-service, but that's a very limited viewpoint. At Stackery we support over 20 different AWS serverless capabilities at this point in time, with Lambda being just one of many.
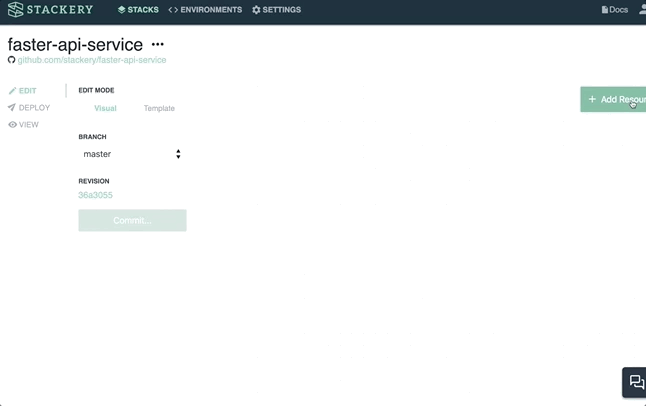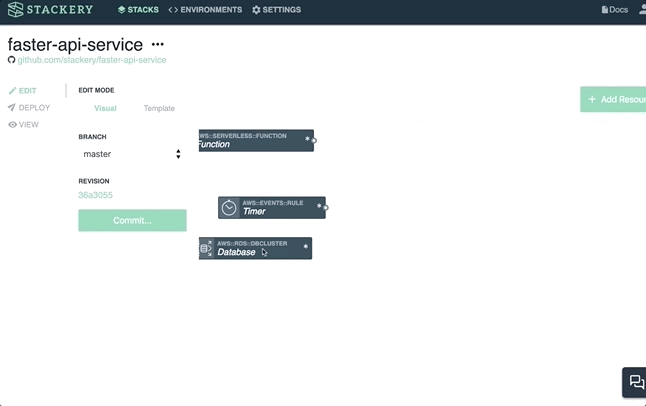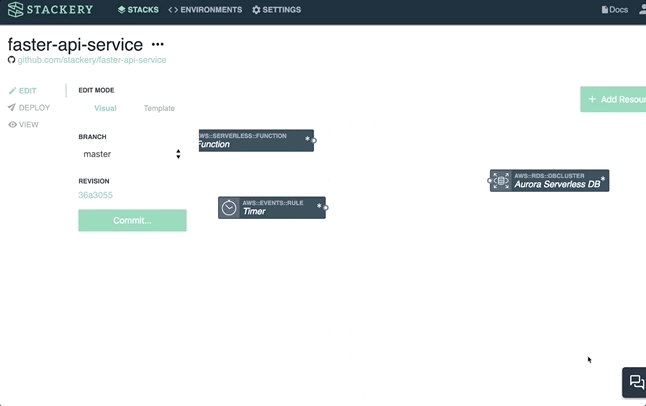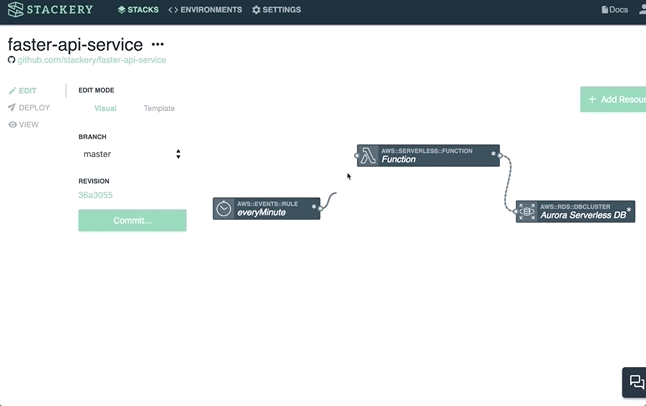
Some purists might argue that if you can't run a service at zero cost until you spin it up at a moment's notice, then it's not truly serverless. Yet there is a broader view of serverless; one where the enterprise is outsourcing all of the underlying management for functions and only paying for usage.
Serverless has the potential to make a real business impact not just as a simple event-based trigger for one specific application function, but rather as a building block for a more agile application infrastructure.
We frequently talk to users and potential customers 'about our mindset of serverless being much broader than any single tool like AWS Lambda. Here’s what we tell teams looking to embrace the full potential of serverless:
Don't focus on the lack of servers, focus on the business logic
What I see happening (and this is true whether you're using AWS or not) is that teams focus more on the logic and the impact that taking a serverless approach has on users and businesses.
To the people building and running serverless applications, it shouldn’t matter if you’re running your architecture in a Kubernetes cluster (with something like Knative) or if it’s managed on-premises or in a public cloud. These teams should be able to build serverless applications successfully and securely deliver and manage them without having to worry about the underlying plumbing.
The way I see serverless, it's not just about your functions, data server, data layer, networking capabilities, or API-calls. No, a modern serverless stack provides a whole set of capabilities that enables users to abstract themselves away from the complexity of the underlying infrastructure to consume services. Understanding this is a critical piece of the puzzle for teams looking to truly benefit from a serverless approach.
Lambda is just one component of a modern serverless stack
This might sound surprising coming from the CEO of a serverless SaaS company, but it’s something we really believe at Stackery: you don't have to have an application that is wholly serverless throughout its entire architecture, and this is an especially important thing to mention to organizations undergoing digital transformation or rethinking their monolithic architecture.
In a logical flow, part of an application's front or back end could be calling out to a database that is not strictly defined as being serverless, under the covers. When organizations choose to build an application in a serverless approach it can drive differentiation in a way that can be important to the functioning of an application.
With serverless, you get to spend your time focused on those things that make you different and better than your competitors and deliver a better experience to your customers. Building an application with a serverless approach allows the enterprise to focus on the business logic, instead of reconstituting the underlying architecture to run a new set of services.
So really, serverless is a whole lot bigger than AWS Lambda, as crucial as that service may be. To unlock the full landscape of serverless capabilities, it’s important to look at how all the services available to you pave a collective path towards clearer business logic.

