Serverless for Total Beginners


As the newest member of the Stackery Engineering team and Stackery’s Resident N00b™, I have been wanting to explain what serverless is in the most beginner-friendly terms possible. This is my attempt to do so.
I recently graduated a full-stack coding bootcamp, where I learned several ways to build and deploy a traditional (i.e. monolithic) web application, how to use containers to deploy an app, but nothing about serverless architecture. It wasn’t until I started my internship at Stackery that I even began to grasp what serverless is, and I’m still learning ten new things about it every day. While the concept of serverless functions and FaaS may seem daunting to new developers, I’ve found that it’s actually a great thing for beginners to learn; if done right, it can make the process of deployment a lot easier.
Above all, serverless is a new way of thinking about building applications. What’s exciting to me as a frontend-leaning developer is that it allows for most of the heavy lifting of your app to take place in the frontend, while cloud services handle typically backend aspects such as logging in users or writing values to a database. That means writing less code up front, and allows beginners to build powerful apps faster than the traditional monolith route.
So let’s dive in with some definitions.
What is a stack, and why are we stacking things?
A stack is essentially a collection of separate computing resources that work together as a unit to accomplish a specific task. In some applications, they can make up the entire backend of an app.
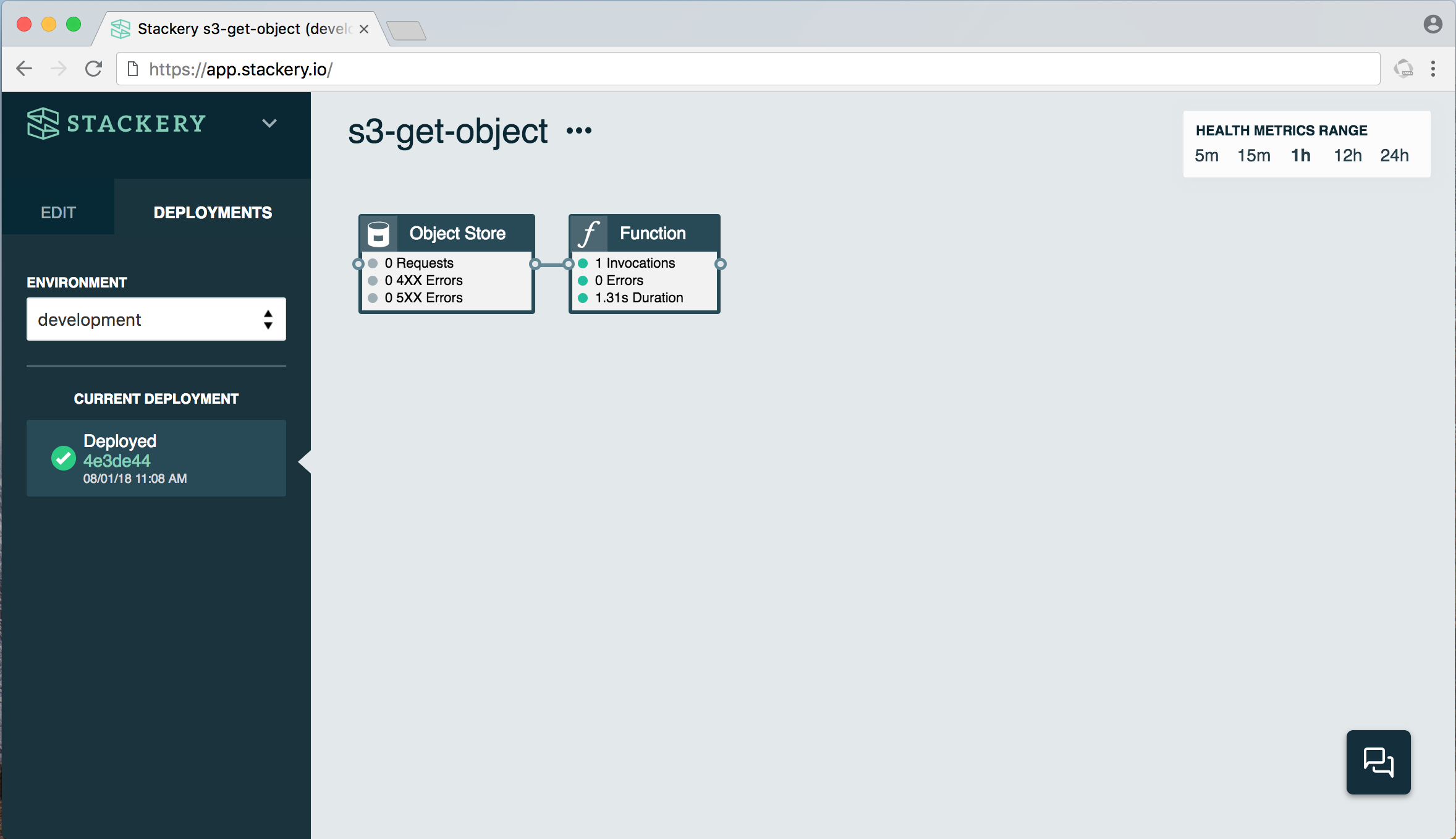
The above example is about as simple as you can get with a stack. It consists of a function and an object store. When triggered, the function manipulates the data stored in the object store (in this case, an S3 bucket on AWS).
A simple use case would be a function that returns a specific image from the bucket when triggered - say, when a user logs into an app, their profile picture could be retrieved from the object store.
Here’s a somewhat more complex stack:
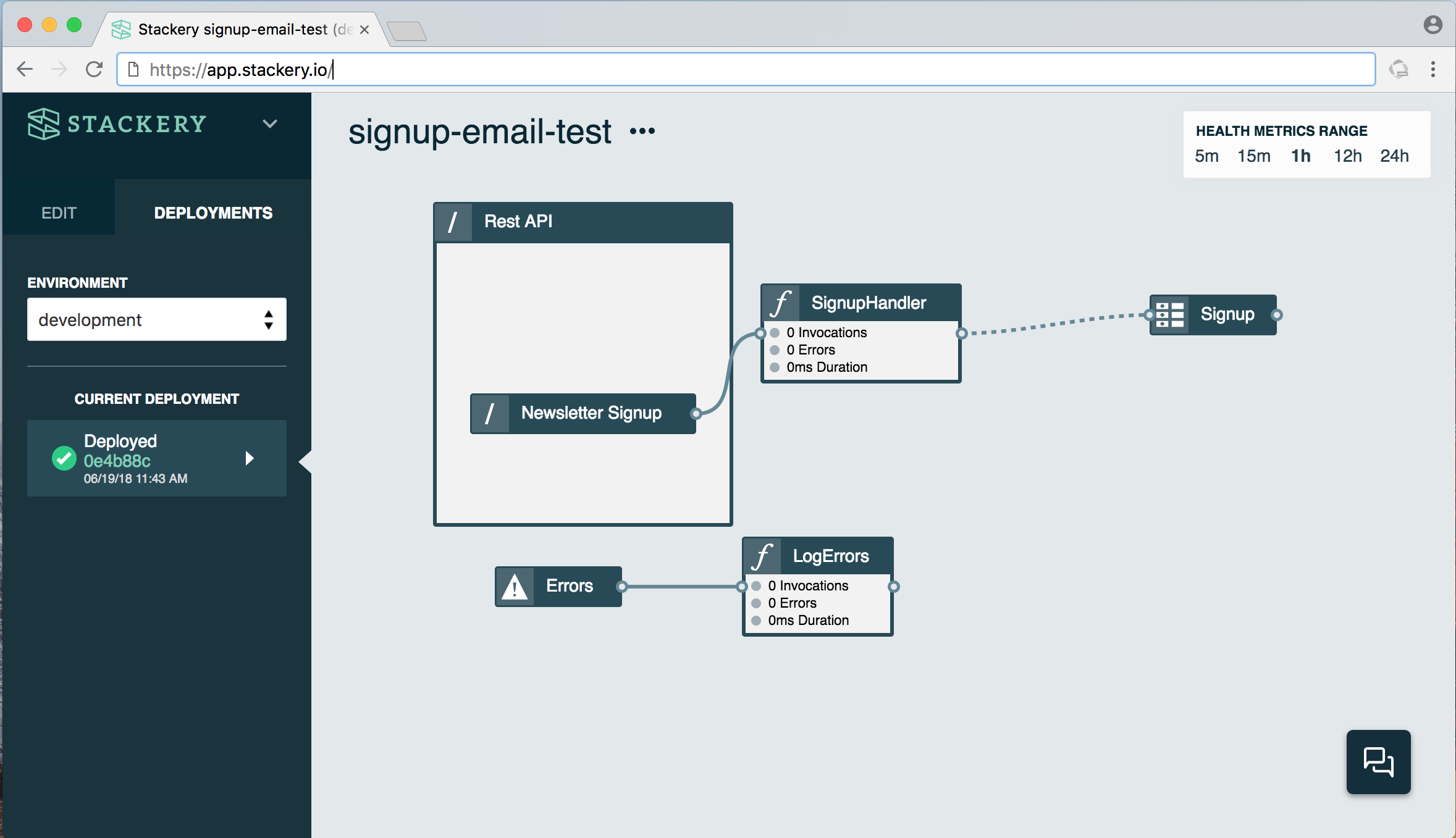
This stack consists of a function (SignupHandler) that is triggered when someone submits an email address on a website’s newsletter signup form (Newsletter Signup API). The function takes the contents of that signup form, in this case a name and email address, and stores it in a table called Signup. It also has an error logger (another function called LogErrors), which records what happened should anything go wrong. If this stack were to be expanded, another function could email the contents of the Signup table to a user when requested, for example.
Under the hood, this stack is using several AWS services: Lambda for the functions, API Gateway for the API, and DynamoDB for the table.
Finally, here is a stack handling CRUD operations in a web application:
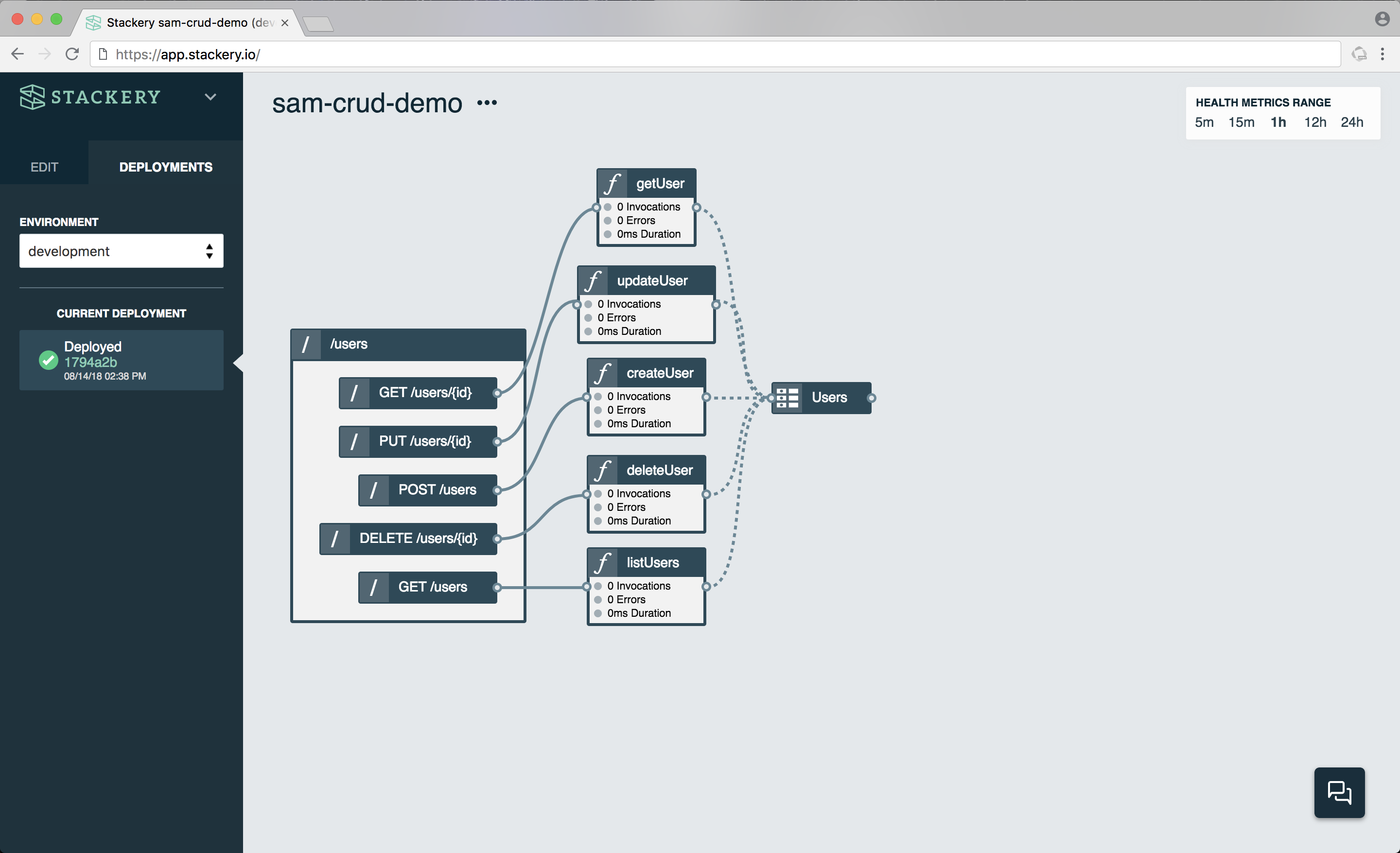
While this looks like a complex operation, it’s actually just the GET, PUT, POST, and DELETE methods connected to a table of users. Each of the functions is handling just one operation, depending on which API endpoint is triggered, and then the results of that function are stored in a table.
This kind of CRUD stack would be very useful in a web application that requires users to sign up and sign in to use. When a user signs up, the POST API triggers the createUser function, which simply pulls up the correct DynamoDB table and writes the values sent (typically username and password) to the table. The next time the user comes back to the app and wants to log in, the getUser function is called by the GET API. Should the user change their mind and want to delete their account, the deleteUser function handles that through the DELETE API.
Are microservices == or != serverless?
There is a lot of overlap between the concepts of microservices and serverless: both consist of small applications that do very specific things, usually as a part of a larger application. The main difference is how they are managed.
A complex web application - a storefront, for example - may consist of several microservices doing individual tasks, such as logging in users, handling a virtual shopping cart, and processing payments. In a microservice architecture, those individual apps still operate within a larger, managed application with operational overhead - usually a devOps team making it all work smoothly together.
With serverless, the operational overhead is largely taken care of by the serverless platform where your code lives. In the case of a function on AWS Lambda, just about everything but the actual code writing is handled by the platform, from launching an instance of an operating system to run the code in your function when it is triggered by an event, to then killing that OS or container when it is no longer needed.
Depending on the demand of your application, serverless can make it cheaper and easier to deploy and run, and is generally faster to get up and running than a group of microservices.
Are monoliths bad?
To understand serverless, it’s helpful to understand what came before: the so-called “monolith” application. A monolith application has a complex backend that lives on a server (or more likely, many servers), either at the company running the application or in the cloud, and is always running, regardless of demand - which can make it expensive to maintain.
The monolith is still the dominant form of application, and certainly has its strengths. But as I learned when trying to deploy my first monolith app in school, it can be quite difficult for beginners to deploy successfully, and is often overkill if you’re trying to deploy and test a simple application.
So serverless uses servers?

Yes, there are still servers behind serverless functions, just as “the cloud” consists of a lot of individual servers.
After all, as the mug says, “There is no cloud, it’s just someone else’s computer”.
That’s true for serverless as well. We could just as well say, “There is no serverless, it’s just someone else’s problem.”
What I find great about serverless is that it gives developers, and especially beginning developers, the ability to build and deploy applications with less code, which means less of an overall learning curve. And for this (often frustrated) beginner, that’s quite the selling point.
Related posts

