Architecting Organizational Excellence for Serverless
Achieve operational and cost management success

Watch a video overview
Companies across sectors are seeing amazing success adopting modern application architectures, especially with managed services like AWS Lambda, DynamoDB, S3, etc. This week Jessica Feng from AWS gave an excellent re:Invent talk: Enabling a serverless-first Cloud Center of Excellence. She described common patterns and traits for organizations who have adopted a "serverless-first" mindset to achieve operational and cost management success.
I'm going to examine the most meaningful aspects driving success within organizations building modern applications. You'll notice that it isn't hard to achieve success if you have a roadmap. But success requires more than just technology alone. It requires involvement and support by people in many different roles.
Modern Application Development Means Infrastructure Development
One of the first things to realize is modern architectures using managed services creates applications that are a network of resources. Applications no longer are "simple" three-tier architectures with a frontend server, a backend server, and a database.
Instead, every time you need to add new functionality to a service you may be adding a new SQS Queue or a new DynamoDB Table. This is why Infrastructure-as-Code (IaC) is a basic tenet of serverless development. From Jessica's slides about infrastructure evolution, adopting a serverless approach means:
The corollary to the above architectural realization is that development teams need to have the autonomy to develop their own infrastructure. For example, a serverless-enabling "Cloud Center of Excellence" focuses on how to provide development teams with AWS accounts, tools, processes, and guardrails to ensure success.
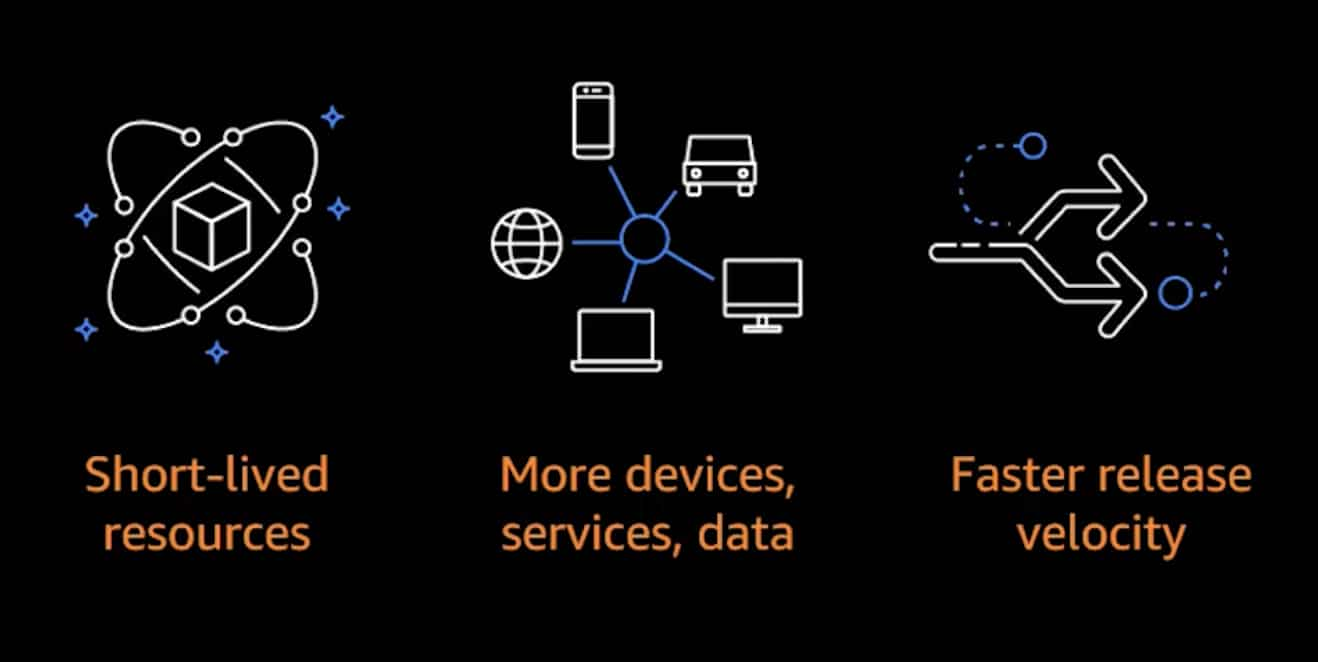
One common pitfall to watch out for is a team creating additional layers of IaC abstractions or templates for reuse. These may have been useful for traditionally stateful infrastructure in the past (e.g. virtual networks and databases), but are more often too restrictive for development teams to achieve their full potential. This happens to be one of my main concerns with the new AWS Proton service in it's current preview release, though I'm excited about its trajectory.
Organizations Need Centralized Excellence for Environments and Deployment Processes
While there are some anti-patterns to watch for, Cloud Centers of Excellence have a very key role to play in helping an organization successfully shift to modern application architectures using managed services. These centralized teams are perfectly positioned to provide development teams with the tools to be autonomous and successful. This slide from Jessica's talk scratched at the surface of what centralized teams can help with:

The following is a further list of needs centralized teams can help provide to enable development team autonomy:
- Environment abstractions for deploying resources, parameterization, and managing secrets (ideally with separate AWS accounts for each environment)
- Identity management so developers can access all the AWS accounts they need (AWS SSO is a huge help here)
- Tools (like Stackery's visual editor 😉) to help developers of all skill levels learn how to develop infrastructure using IaC and ensure permissions and configuration are properly scoped by default
- Turn-key CI/CD capabilities to make it easy for development teams to implement automated testing, vulnerability scanning, and a mixture of automated and manual checks as part of a deployment pipeline
Of course there are many more things a centralized team can help provide for the organization. For example, DevSecOps additions to the CI/CD pipeline can be added to ensure security and best practices. The key is to focus on the needs that offload work from development teams while reducing dependencies that slow them down.
Share Wins and Insights
Lastly, success does not happen in a vacuum. While this can be read to mean that success does not happen without input from others, it can also be interpreted to mean success involves sharing with others. Jessica shared this slide showing how teams can spread success even after just the first pilot projects are complete:
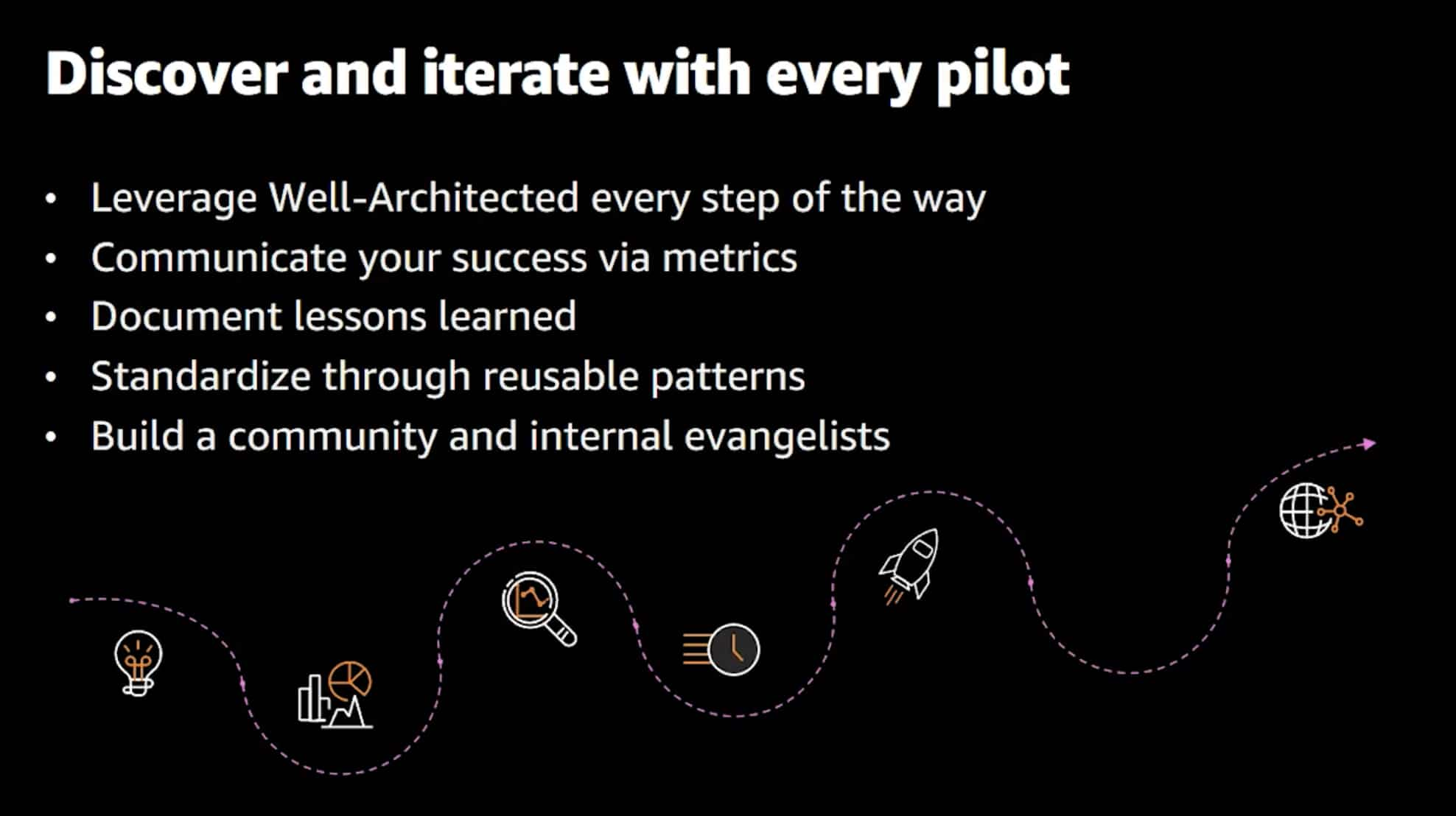
This is especially true as adopting new architectures and practices requires process and cultural shifts. Sharing success stories and insights is the best way to overcome the inertia of existing practices.
Centralized Practices Will Lead To Organizational Success
No matter whether your organization has a dedicated Cloud Center of Excellence or simply a way to share wins and insights, it is important to identify and centralize practices. If serverless is new for your organization, find and propose a pilot project, then find ways to share your learnings with everyone who will listen. Then continue iterating and codifying best practices so more and more people can follow in your footsteps. Eventually you will end up transforming into your own "serverless-first" organization that ships faster and scales higher!
Want to chat more about IaC, Centralized IT, or Stackery? Schedule a chat (and we will send you coffee).
Related posts

Truly composable and maintainable CloudFormation is now within reach

How will we build apps in the years to come? Werner gave us insights in his re:Invent keynote



The Stackery team combed the schedule to find the must-attend events

Or, how to consume re:Invent content to build better apps today