The Anatomy of a Serverless App


Serverless has, for the last year or so, felt like an easy term to define: code run in a highly managed environment with (almost) no configuration of the underlying computer layer done by your team. Fair enough, but what is is a serverless application? A Lambda isn’t an app by itself, heck, it can’t even communicate with the world outside of Amazon Web Services (AWS) by itself, so there must be more to a serverless app than that. Let’s explore a serverless app’s anatomy, the features that should be shared by all the serverless apps you’ll build.
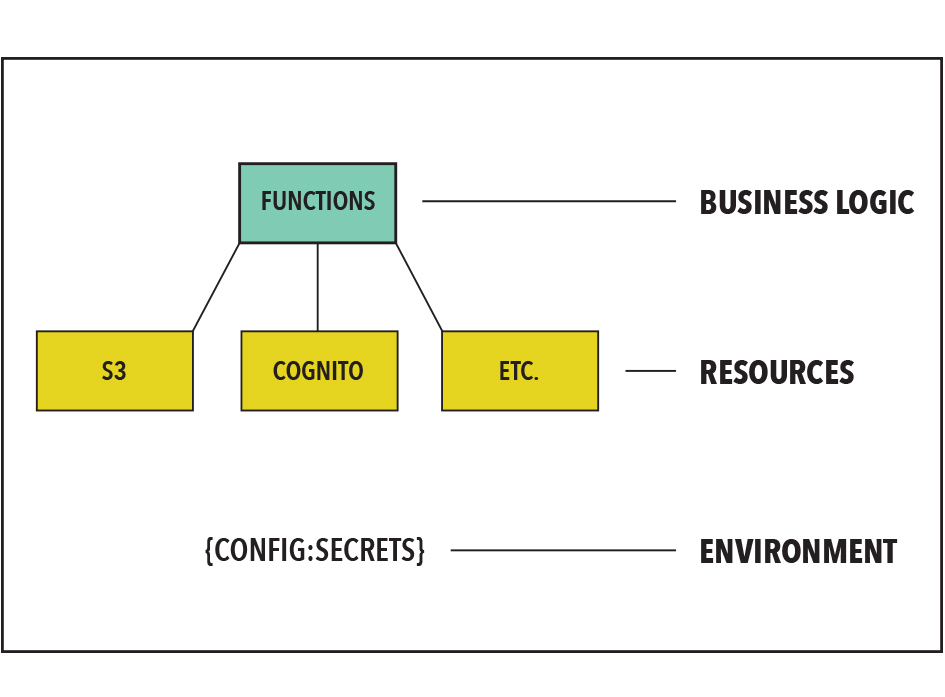
Serverless applications have three components:
- Business logic: function (Lambda) that defines the business logic
- Building Blocks: Resources such as databases, api gateways, authentication services, IOT, Machine Learning, container tasks, and other cloud services that support a function
- Workflow phase dependencies: Environment configuration and secrets that respectively define and enable access to the unique dependencies unique each phase of development workflow.
Taken together, these three components create a single ‘Active Stack’ when running within an AWS region.
Review: What’s a Lambda?
I could write this piece in a generic tone and call Lambdas ‘Serverless Functions,’ after all, both Microsoft and Google have similar offerings. But Lambdas have fast become the dominant form of serverless functions, with features like Lambda Layers showing how Lambdas are fast maturing into an offering both the weekend tinkerer and the enterprise team can use effectively.
But what are Lambdas again? They’re blobs of code that AWS will run for you in a virtualized environment without you having to do any configuration. It might make more sense to describe how Lambdas get used:
- You write a blob of Node, Ruby, or several other languages, all in the general mode of ‘take in a triggering event, kick off whatever side effects you need to, then return something’
- Upload your code blob to AWS Lambda
- Send your Lambda requests
- AWS starts up your code in a virtual environment, complete with whatever software packages you required
- Look at the response!
- Send your Lambda 10,000 requests in a minute
- AWS starts up a bunch of instances of your code, each one handling several requests
- Look at all these responses!
Are Lambdas like containers? Sort of, in that you don’t manage storage or the file system directly, it should all be set in configuration. But you don’t manage Lambda startup, responses, or routing directly; you leave all of that to AWS.
Note that Lambdas do not handle any part of their communication with the outside world. They can be triggered by events from other AWS services but not from direct HTTP requests, for that a Lambda needs to be connected to an API gateway or more indirectly to another AWS service (E.G. a Lambda can respond to events off an S3 bucket, which could be HTTP uploads)
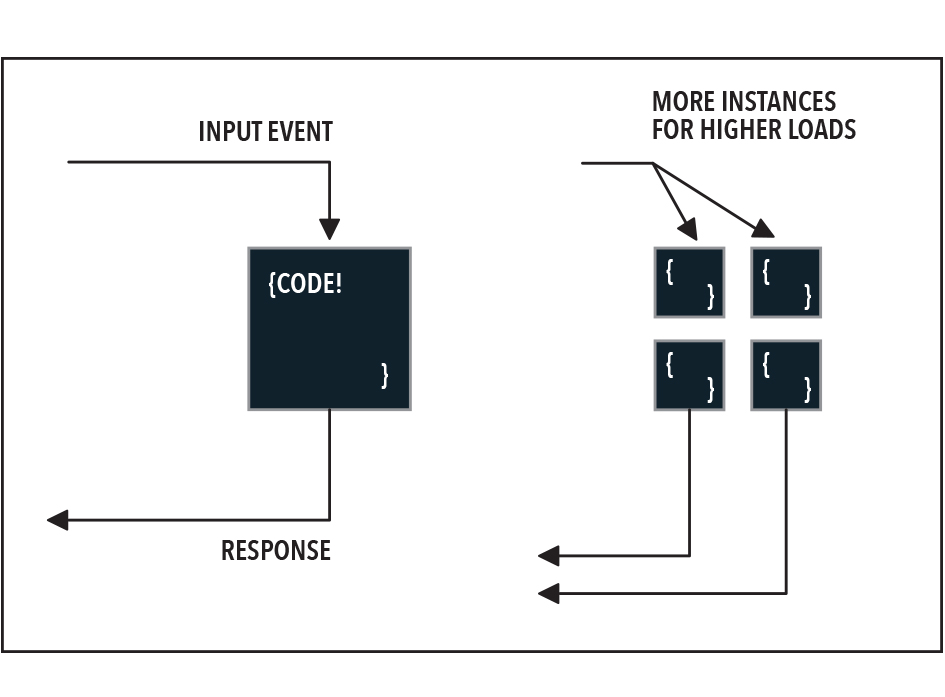
What supports our Lambdas?
We’ve already implied the need for at least one ‘service’ outside of just a Lambda: an api gateway. But that’s not all we need: with a virtualized operating system layer, we can’t store anything on our Lambdas between runs, so we need some kind of storage. Lambdas shouldn’t be used for extremely long running tasks, so we need a service for that. Finally it’s possible that we want to make decisions about which Lambda should respond based on the type of request, so we might need to connect Lambdas to other Lambdas.
In general, we could say that every function will have a resource architecture around it that lets it operate like a fully featured application. The capabilities and pallet of offerings of this resource architecture continue to expand rapidly, both in terms of the breadth of offerings for IoT, AI, machine learning, security, databases, containers, and more as well as services to improve performance, connectivity, and cost profiles.
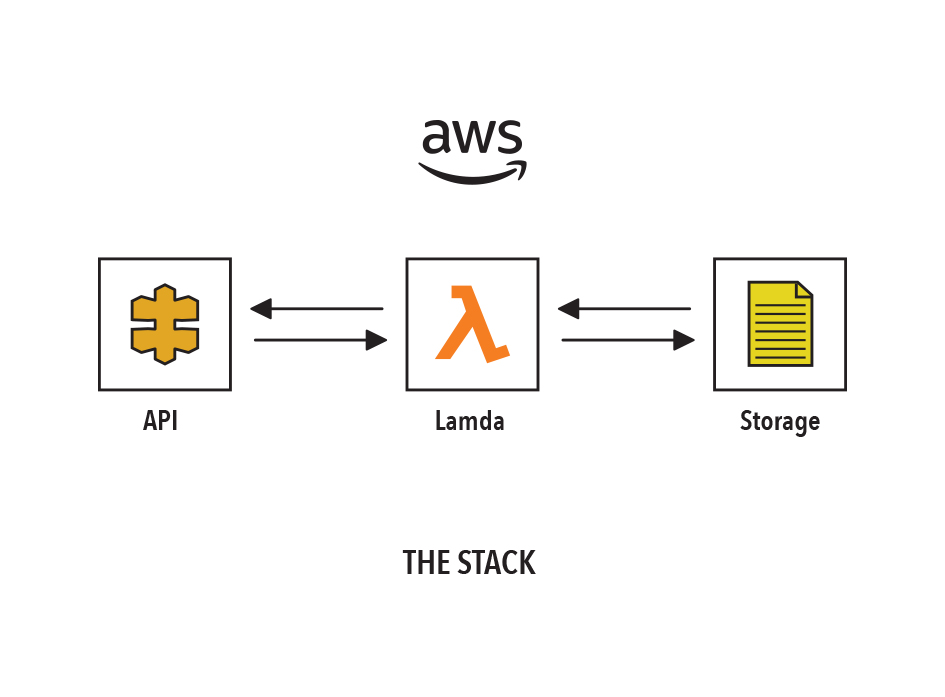
With all these necessary pieces to make a Lambda do any actual work, AWS has a service to let us treat all these pieces as a unit. CloudFormation can treat a complete serverless ‘stack’ as a configuration file that can be moved and deployed in different environments. With Stackery you can build and stacks from an easy graphical canvas and the files it produces are the same YAML that CloudFormation uses natively!
Secrets
Lambdas are blobs of code that should be managed through normal code sharing platforms like Github. Two problems present themselves right away: How do we tell our Lambda where its running, and how do we give it the secrets that it needs to interact with other services?
The most common example of this will be accessing a database.
Note: If we’re using an AWS-hosted serverless database like DynamoDB the following steps should not be necessary since we can handle giving permissions to the Lambda for our DB within the Lambda’s settings. Using Stackery to connect Lambdas to AWS databases makes this part as easy as drawing a line!
We need secrets to authenticate to our DB, but we also need our Lambda to know whether it’s running on staging so that it doesn’t try to update the production database during our test runs.
So we can identify three key sections of our serverless app: our function, its resources, and the secrets/configuration that make up its environment.
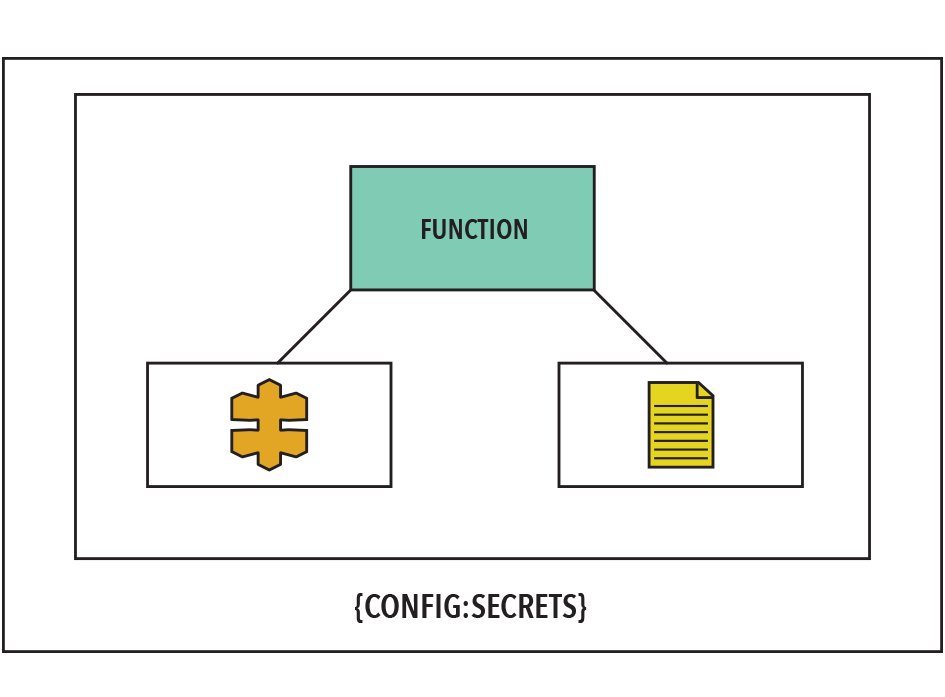
The Wider World
In a highly virtualized environment, it’s counter-intuitive to ask ‘where is my code running’ but while you can’t put a pin in a map you must spread your app across AWS availability zones to ensure true reliability. We should therefore draw a box around our ‘environment’ with our stack, its configuration, and secrets. This entire system will exist across multiple zones or even in services other than AWS (if you really enjoy the headache of writing code and config for multiple clouds).
How many ‘Active Stacks’ is your team running?
An active stack is a complete set of functions, resources, and environment. If you have the same function code and resources running on three environments (e.g. dev, test, and prod) you have three active stacks. If you take your production stack and distribute it to three different AWS regions, you again have three active stacks.
How this anatomy can help your team.
Identifying unifying features is not, in itself, useful for your team, but it is an essential step in planning. We cannot adopt a serverless model for part of our architecture without a plan to build and manage all these features. You must have:
- Programmers to write your functions and manage their source code
- Cloud professionals to assign and control the resources those functions need
- Operations and security to deploy these stacks in the right environments
You also need a plan for how these people will interact and coordinate on releases, updates, and emergencies (I won’t say outages since spreading your app across availability zones should make that vanishingly rare).
Later articles will use this understanding of the essential parts of a serverless app to explore the key decisions you must make as you plan your app.
How Stackery Can Help
Now that we’ve defined these three basic structures, it would be nice if they were truly modular within AWS. While lambda code can easily be re-used and deployed to different contexts, It’s more difficult to use a set of resources or an environment like a module that you can move about with ease.
Stackery makes this extremely easy: you can mix and match ‘stacks’ and their environments, and easily define complete applications and re-deploy them in different AWS regions.
Related posts