Implementing the Strangler Pattern with Serverless

By now we've all read Martin Fowler's Strangler Pattern approach to splitting up monolithic applications. It sounds wonderful, but in practice it can be tough to do, particularly when you're under a time crunch to enable shiny new "modern" features at the same time.
An example I've seen several times now is going from an older, on-prem, or in general just slower, traditional architecture to a cloud-based, event-streaming one, which enables things like push notifications to customers, high availability, and sophisticated data analytics. This can seem like a big leap, especially when you've got an application that is so old most of your engineering team doesn't know how it still functions, and is so fragile that if you look at it wrong it'll start returning java.null.pointer .html pages from its API.
Here's the good news, serverless can help you! Stackery can help you! By creating serverless API layers for your existing domains, you can abstract away the old, exposing painless restful API interfaces to your frontends, while simultaneously incorporating event streaming into your architecture. Furthermore, by using Stackery, you can do this while maintaining a high degree of monitoring (with our Health Dashboard), operations management, and security (since we configure the IAM permissions between services, handle environments, and encrypt configuration storage, for you).
The Situation
Let's take a hypothetical customer loyalty application. It has some XML based Java API's that map to some pretty old, non-restful application logic. The application works as is, if slowly, but the cost of maintaining it is getting too high, it's fragile and prone to tip overs, and we've got a directive to start abstracting away some of it into some sort of new cloud-based architecture on AWS. We also want to justify some of this refactor with some new feature enablement, such as push notifications to customer's phones when they reach a certain loyalty tier or spending cash back amount, and an event-based data analytics pipeline.
Steps to Enlightenment
- Use Domain Driven Design techniques to define a new, cleaner, microservice-like understanding of your application. Including events that you want to surface.
- Define your new API contracts based on these new domains. In our example, the domains are pretty straightforward, loyalty and customer, perhaps before they were combined into one, but as we add more loyalty based functionality we've decided to separate them for future proofing and ease of understanding.
- Define how your old APIs map to these new APIs. For example, say we want to enable a new POST /customer endpoint. Previously, the frontend had to send an
XML request to service x and an XML request to service y. We will encapsulate and abstract that logic away in our serverless API function. - Build your new architecture!
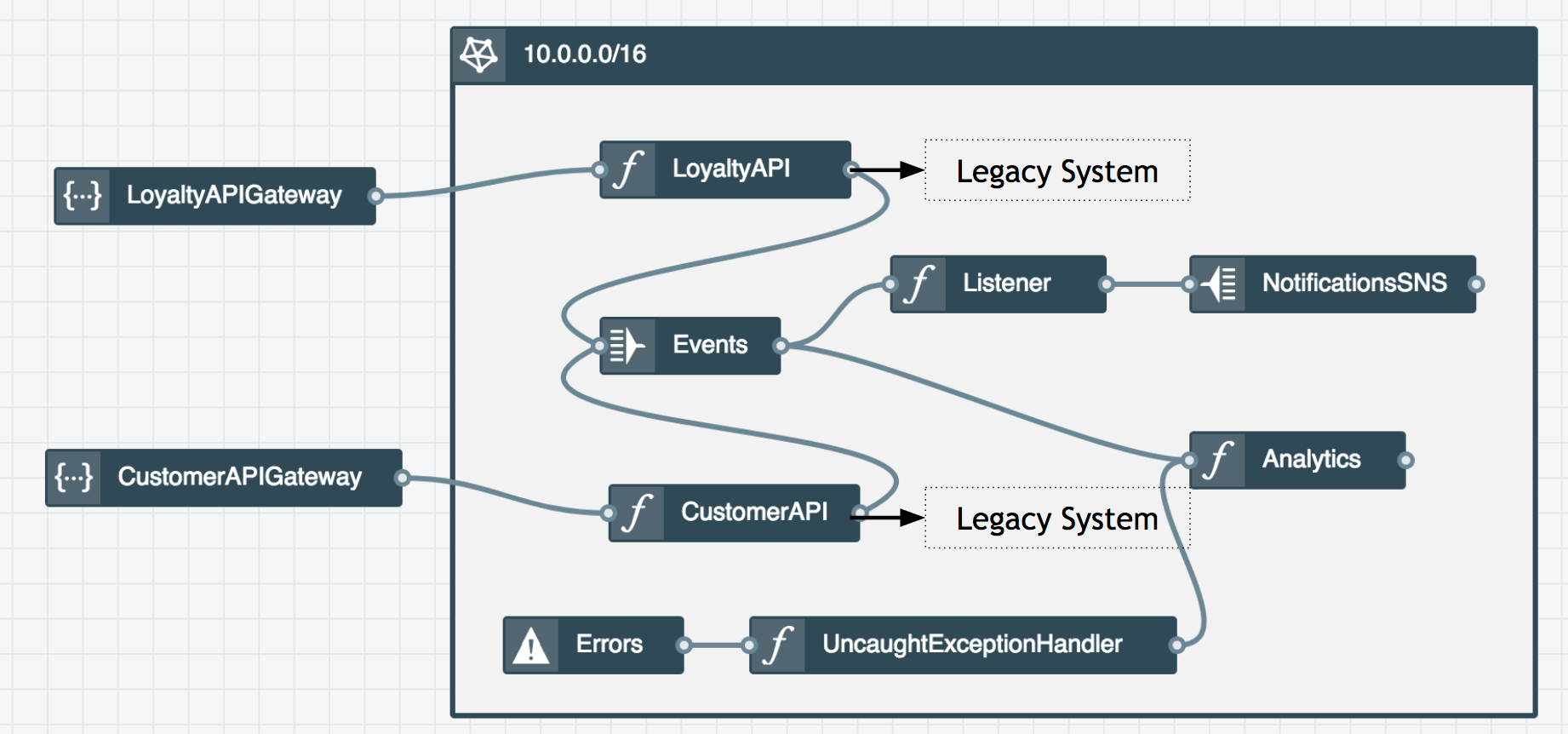
Above, I have laid out a hypothetical strangler pattern-esque architecture in Stackery's editor panel to solve the situation.
We have two Rest API Nodes corresponding to the two new domains, that front and forward all requests to two Function Nodes, CustomerAPI and LoyaltyAPI which would be implementing our new API contract, combined with any abstracted-away logic dealing with the underlying legacy application to enable this contract. So far we have achieved the essential goal of the strangler pattern by abstracting away some of our old logic, and exposing it via new domain driven, segmented APIs.
Now for enabling some new functionality. These API nodes, in addition to returning respondes to the frontend, emit contextual events to the Events Stream Node, which in turn outputs to the Listener Function Node that listens for customer or loyalty events it "cares" about. Those events are forwarded on to a NotificationsSNS Topic Node, enabling event-based SNS. We also have an Analytics Function Node, that gets events from the event stream as well as any error events. The Errors node emits any uncaught errors from our new functions to the UncaughtExceptionHandler Function Node for easier error management and greater visibility.
Conclusion
Not all legacy application migrations will follow the steps I've listed here. In fact, one of the biggest struggles with doing something like this is that each strangler pattern must be uniquely tailored based on an in-depth understanding of the existing business logic, risks, and end goals. Often times, the engineering team implementing the pattern will be somewhat unfamiliar with some of the new technology being used. That also comes inherently with risk such as...
- What if it takes too long to PoC?
- What if you configure the IAM policies and security groups incorrectly?
- What if something breaks anywhere in the pipeline? How do we know if it was in the new API layer or the old application?
When one migrates to distributed cloud-based services, it's more complicated than it's made out to be. Stackery can help you manage these risks and concerns, by making your new applications faster to PoC, managing secure access between services for you, and surfacing errors and metrics. There are a lot of things that can go wrong, and AWS doesn't make it easy to find the problem. There's also the task of fine tuning all these services for cost efficiency and maximum availability. Ask yourself if you would rather be doing that by digging through the inception that is AWS's UI, or with Stackery's Serverless Health Dashboard.
Related posts