Building Serverless State Machines

State machines are useful mechanisms for decoupling logic flow from computation. They can be used to refactor complex spaghetti code into easy, understandable statements and diagrams. Further, state machines are built upon a mathematical model, which provides the ability to "prove" whether they correctly implement desired functionality.
A little over a year ago, AWS released Step Functions, their service built on top of AWS Lambda to provide state machine logic flow. The best way to describe Step Functions in terms of state machines is to equate the states in a state machine with invocations of Lambda Functions, and state transitions as the evaluations of the results of the invocations. Here's an example AWS Step Function diagram:
Microsoft has a similar service called Azure Logic Apps. Both Logic Apps and Step Functions provide a powerful abstraction layer on top of bare Functions-as-a-Service (FaaS) services. However, these services have one glaring issue: they are too expensive for high-throughput applications. Instead, these services cater to "business logic" use cases. Some examples:
- Customer account onboarding
- Contract approvals
- Paperwork-to-electronic-record synchronization
These scenarios benefit from auditing and the ability for state machines to exist over a long period of time (potentially up to a year in length). Unfortunately, providing these features drives cost up to the point that the services are not a great fit for high-throughput applications.
That said, it is still very possible to build serverless applications using state machine models. There are two key mechanisms we need to build serverless state machines: concurrency coordination and state transition logic.
Concurrency Coordination
One of the primary features of FaaS is the ability to easily scale the number of simultaneous invocations of functions. One typical use case example is performing a MapReduce computation, where a large data set is split into smaller chunks that are processed by a reducer function in parallel. This is easily accomplished using serverless techniques, excepting one issue: how can you tell when the last reducer function has completed?
External state is the primary mechanism for providing concurrency coordination. The state can be stored anywhere with atomic operations. Great fits in the serverless ecosystem are Key-Value stores like AWS DynamoDB and Azure CosmosDB. These stores are serverless, cost-effective, and horizontally scalable.

The following are the basic steps to perform coordination among concurrent function invocations for a MapReduce algorithm:
- A mapper function splits the data set into chunks
- The mapper function counts the total number of chunks and inserts the count into the external state data store (this represents the total number of in-process function invocations)
- The mapper function invokes the required number of reducer functions in parallel to process each chunk
- When each reducer function invocation completes, it atomically decrements the count of in-process invocations in the external state data store
- If the count of in-process invocations is zero, then the current reducer function is the last to complete and the system can continue onto the next state in the state machine
There are many other ways concurrency may need to be coordinated, but they all share the property of needing to track state in an atomic, external store.
State Transition Logic
This brings us to state transitions. How can one function invocation make the proper decision on which function(s) should be executed next? At first glance, this doesn't sound too difficult. We are used to writing this sort of logic directly in our function source code. But embedding the logic of a state machine in the source code of all its functions leads to the spaghetti code mess we are hoping to avoid by using a more formal state machine model.
To inch our way towards a more general approach to state machine transition logic, let's take a look at a simple use case: custom retry logic. In this example, the process performed for state "A" in the diagram below should be retried up to MAX_RETRIES.
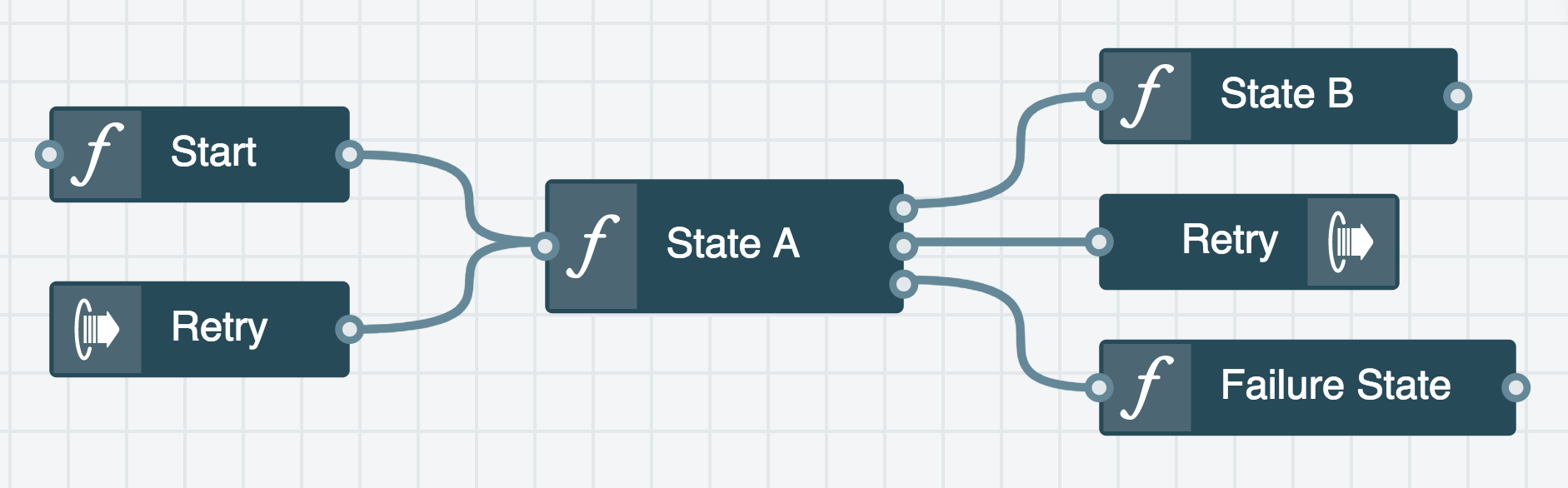
Upon success, the logic transitions by invoking the function for state "B". But let's focus on the failure scenario.
Function A is invoked with a message. That message may look something like:
{
userId: 12345
}
When a failure occurs, function A looks at the input message to see if it has a retries property. It does not, so function A adds the property with a value of 1:
{
userId: 12345,
retries: 1
}
Then, function A can re-invoke itself with the newly update message. If it fails again, it now increments the retries property:
{
userId: 12345,
retries: 2
}
Each time a failure occurs, the number of retries is compared against the MAX_RETRIES value. If the number of retries exceeds MAX_RETRIES, then the state machine can transition into a failure state. This may include pushing the input message onto a dead letter queue or notifying someone of the failure.
The key here is that the state of the machine can be passed as part of the input into the function. This is a powerful mechanism for managing the logic flow of an application.
A Generic Serverless State Machine?
While the above mechanisms for concurrency coordination and state transitions can be used to build bespoke state machines, it would be great if we could use a standard state machine specification to build general logic flows. While this has yet to be completely achieved, there have been some promising attempts. One example is Ben Kehoe's Heaviside project. Heaviside attempts to provide both the state machine definition and state to functions via AWS Lambda's Context mechanism using the same Amazon States Language specification used for Step Functions. While this works in theory, it breaks down in practice because AWS Lambda doesn't support providing arbitrary context data when invoking functions asynchronously. This is an impediment to implementing state machines where the machine definition and state are passed separately from the input messages. It would be interesting to investigate whether mixing the state machine data with the input message could achieve the desired result.
Even with the current challenges, I'm excited to see the progress being made in pursuit of serverless state machines. I believe it is only a matter of time before someone builds a generic framework on top of existing FaaS solutions and/or cloud providers support high-throughput state machines.
Related posts

