Serverless Function Architecture Principles

 Serverless services are often called "Functions-as-a-Service", or FaaS. The use of the term "function" arose because we needed a name for a compute unit that was smaller than a "server" or "container". But how should you break your implementation down when building a serverless architecture? Unfortunately, thinking in terms of "functions" tends to create problems.
Serverless services are often called "Functions-as-a-Service", or FaaS. The use of the term "function" arose because we needed a name for a compute unit that was smaller than a "server" or "container". But how should you break your implementation down when building a serverless architecture? Unfortunately, thinking in terms of "functions" tends to create problems.
Let's start by talking what what serverless "functions" actually are.
What is a serverless "function"?
A serverless "function" is simply code that runs in response to an event. That's it.
The problem with calling these constructs "functions" comes when we start to design a service. Software engineers are trained to break complex tasks down into a series of small, testable components of code we also call "functions". Should we apply the same heuristics to serverless "functions" as we do source code "functions"?
Applying source code "function" architecture is the approach many new serverless users take when building their services. I was reminded of this recently when someone asked me how to implement a service that did a few things in sequential order. Their thinking was to architect the service like they would a program by encapsulating each step of functionality in a separate serverless "function". While conceptually it makes sense to break down the steps into independent units, in practice this is an anti-pattern.
Many Functions Leads To Many Problems
Let's first tip-toe around the issue of complexity and separation of concerns when talking about how to architect a serverless service. We'll come back to address these issues. Instead, let's focus for now on concerns that can be objectively measured.
Imagine you have a pipeline of serverless "functions" to handle a web request. In its simplest form, this may look like an api endpoint that passes a request onto function A that then proxies the request onto one of two different functions, B and C, depending on some criteria. When either function responds, the response is proxied back through function A to be transmitted back to the client through the api gateway.
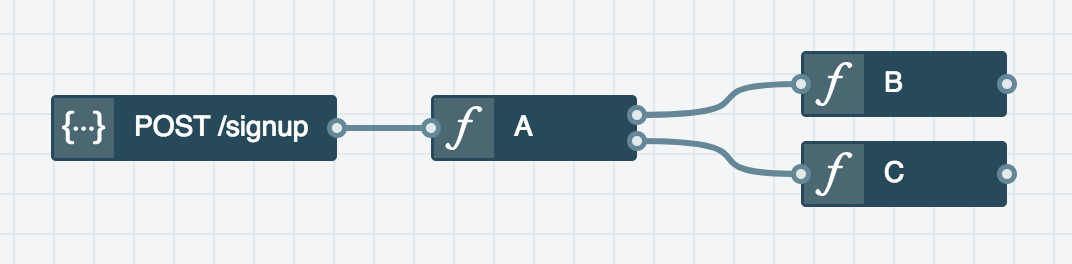
There are two objective cost increases associated with this architecture. First, for every request you are running twice as many functions instead of one, because function A will need to sit idle and wait until either function B or C handles the request and sends a response back. This doubles the compute cost compared to having one function do all the work. The second cost is latency. There is latency when invoking a function, which is even worse when the invocation causes a "cold start". Calling two functions doubles this latency.
Most people do not attempt to build serverless services using the above architecture, but it's not unheard of. Let's take a closer look at a more prevalent paradigm: decomposing functionality into independent functions.
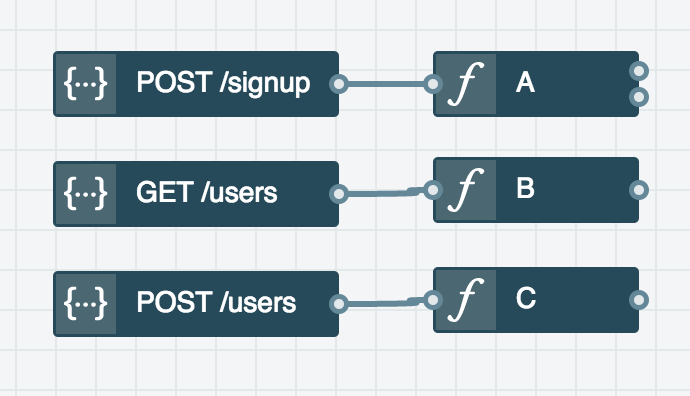
Let's say you have an API service with a mapping of endpoints to independentent serverless "functions". Arguments can be made on whether decomposing endpoint functionality helps or hinders abstractions and composition of code. However, at an objective level we have added a cost to the system: more frequent "cold starts". Cold starts occur when a function runtime isn't cached and must be initialized. If all of an API service's endpoints are handled by one "function", then that "function" can be initialized, cached, and reused no matter which endpoint of the API is invoked. In contrast, when using independent functions each one will incur its own cold start penalty.
Resolving The Functions-as-a-Service Impedence Mismatch
Impedence mismatch is a term borrowed from an analogous concept in electrical engineering. It stands for a set of conceptual and technical difficulties that are often encountered when applying one set of concepts and implementations to another, like mapping a database schema to an object-oriented API.
The architectural issues outlined above follow from attempting to apply a "function" programming model to what is actually an event handling service. FaaS services are really event handling services that the term "function" has been grafted onto. Instead of trying to map our ingrained understanding of the term "function" onto event handling services, let's instead architect our code around building a unit of functionality.
Let's imagine the following service built with many black-box "functions" hooked together:
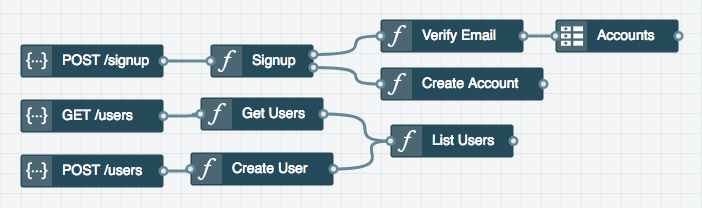
Let's now transform it into a simpler architecture:

Now we can dive into a discussion of which approach is better. The better approach will facilitate the following:
- Lower costs (both in money and in performance)
- Ease of integration testing
- Ease of other people understanding the architecture
The first two points are self-evident, but the last one is particularly important for teams of developers who must share a common understanding of the service architecture.
We discussed above how reducing the number of "functions" reduces the hard costs of serverless computing. Let's focus now on the other two concerns.
Integration testing is difficult in general because you are attempting to test one unit of functionality you do control with other units you don't control. While it's tempting to believe you do control all the serverless "functions" in your service, you don't really control the boundaries between them. By consolidating functionality into fewer "functions" you minimize the integration boundaries, which makes it easier to build more meaningful integration tests that cover larger amounts of functionality.
Lastly, when it comes to understanding service architectures it is almost always easier when there are fewer parts. This is why most services start out as monoliths. Obviously, there are times when services do need to be decomposed, but this generally occurs when one service has become too large for a single team of engineers to manage. At that point the decomposition occurs because the amount of code that makes up the service is orders of magnitude larger than the amount of code we are concerned with when we consider serverless "function" composition. But this does lead us to a question about how to architect a larger amount of code so it is still easy to comprehend.
Separation Of Concerns
Separation of concerns is a design principle that helps guide effective code structure. It stresses modularization to achieve units of code that are easily understood as independent pieces of functionality. If we consolidate functionality from modular serverless "functions" into more monolithic "functions", aren't we breaking this design principle?
It's true that on one level consolidation of functionality means there may be less separation of concerns at the infrastructure level. However, that does not mean we have to foresake the principle altogether. One of the tenets of the Node.js ecosystem is that all functionality should be packaged into modules. Serverless functions don't need to be written in Node.js, but the Node.js ecosystem provides a good example of the power of modularity in source code implementations. We can use this source code modularity to provide separation of concerns in our service.
Let's look at one example where separation of concerns can be moved from infrastructure design to the source code. Let's say we want to add A/B testing functionality to an API, where randomly some requests are executed with one of two different implementations. We want to have a separation of concerns where one part of the service handles the A/B test independently from each of the two implementations. This could be achieved with the following architecture:
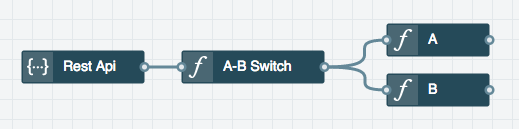
However, as we saw above this would add significant cost to the solution in terms of compute resources and latency. Instead, we could achieve the same result by putting each of the two code paths into separate modules and invoking them from within a single function. The two code paths could even be just different revisions of the same code, enabling a slow rollout of new functionality. While the mechanism is different in each programming language, there are means to enable referencing specific versions of modules in all modern runtimes. For example, a Node.js module may be kept in github and referenced with different versions by putting the following in package.json:
{
...
"dependencies": {
"a": "org/repo#v1.2",
"b": "org/repo#v1.3"
},
...
}
Then the top level source code for the function would be something like:
module.exports = handler(message) {
if (Math.random() < 0.9) {
return require('a')(message);
} else {
return require('b')(message);
}
}
This approach is an example of how we can use source code architecture instead of infrastructure architecture to implement separation of concerns. Our top level function source is concerned only with the A/B test, and we leave the implementation up to the different module implementations.
Serverless Function Architecture Principles
The concerns above lead to a few key serverless "function" architecture principles:
- Build each "function" so it performs as much as it can independently of other services
- Evaluate objective, hard costs of choices above subjective costs related to "function" composition
- Investigate functional composition via code implementation mechanisms when faced with separation of concerns issues
These principles will guide you to more efficient and manageable serverless implementations.