re:Invent Serverless Talks - Scaling Up to Your First 10 Million Users

After months of planning and anticipation for sponsors, attendees, and speakers alike, it’s a bit surreal that re:Invent 2019 is actually upon us!
In addition to setting up shop in the Expo hall with the team to chat with re:Invent guests about their current serverless development workflows (and how Stackery can supercharge it), I made sure to attend some choice presentations this week. Since you’ll probably find a million keynote recaps, I’ll leave the write-ups to those many authors.
Instead, I’d like to share my reflection on some of the smaller serverless-related talks and activities we’re loving at re:Invent 2019. Stay tuned for more throughout the week!!
Day 1: Monday, December 2, 2019
ARC211-R Scaling up to your first 10 million users by Brian Farnhill and Hong Pham, Solutions Architects @ AWS.
This talk was fantastic and I’m glad it’s the one I chose to kick off re:Invent. In general, it provided an overview of the best AWS tools to use when scaling your application. Naturally, there was a lot of talk about serverless in this presentation given its inherently scalable results.
Brian Farnhill began by polling the audience about their respective users: “Who in the audience has between 1 and 1,000 application users” and so on until he arrived at “tens of millions” to which nary a hand shot up.
“A handful of people here have a million or so users,” said Brian “ -- and no company arrives at a million users (or 10 million) without networking. Talk to one another.” Touché.
From there, Brian addressed auto-scaling and the misconception that this was NOT the one-size-fits-all starting point for growing your user base. “If it was,” he joked “this would be the end of our talk.”
The rest of the presentation was essentially a guide to arriving at the next bracket of user count knowing that auto-scaling isn’t the best place to start. The actual answer? Using specific development workflow best practices and AWS tooling tailored to your user count. We couldn’t agree more.
But here’s the rub: the vastness of re:Invent 2019 (65k registered attendees!) is pretty representative of the vastness of AWS itself: with so many services (170+) and an immense global infrastructure (22 geographic regions, 69 availability zones, etc.) how does one begin to scale their AWS apps?
Here was the breakdown that Brian and Hong offered:
Users 1-1000
Brian described a cycle for considering your scalability plan: Build, measure, and learn. When you get stuck at one step, you have to return to the previous one. This makes perfect sense and really you have no other path; after all, you need to be able to measure your app to be able to identify bottlenecks. If you do identify bottlenecks in the “measure” phase, you have to go back to the building phase. Checks out.
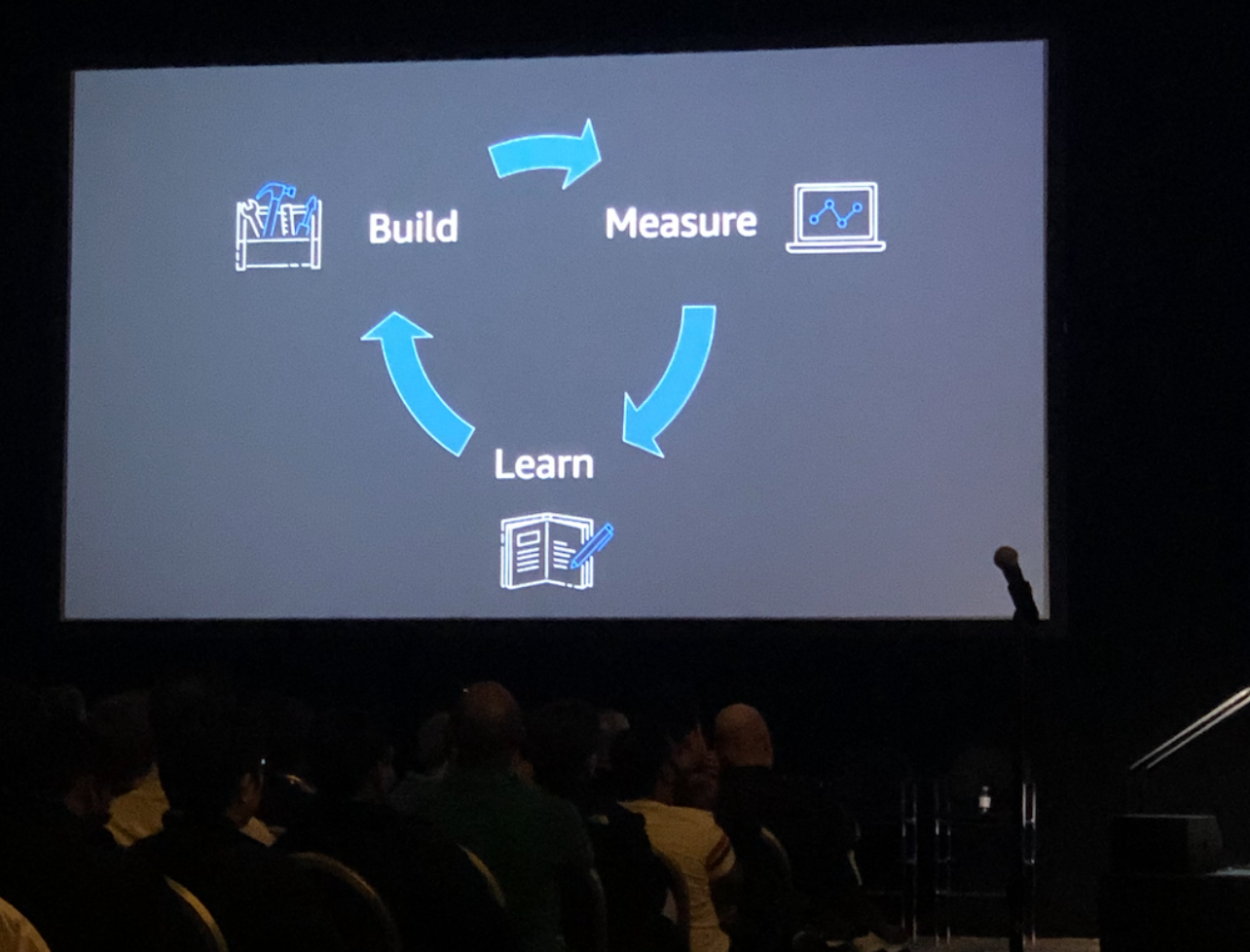
In this section of the talk, the part I found particularly elucidating was Brian’s analysis of AWS tooling and where they should be introduced into your development practice based on user count. I’ll get back to this with an aside/caveat in a moment.
True, those 170+ AWS services mean you get to cherry-pick the perfect components for your unique architecture, but that doesn’t mean you should “drink the ocean” and guzzle tools like you’re dying of thirst. Some AWS tools that are more scalable than others so you need to be strategic about which ones are used first if you want to scale to 10 million+.
Here is a breakdown of the more vs less scalable AWS tools. Hint: more scalable (left) means you should start there:

Now for my personal aside/caveat:
The first service in that right-hand column is Amazon EC2, which provides secure, resizable compute capacity in the cloud. One common serverless application includes a Virtual Private Cloud (VPC) resource and a Bastion host (EC2 instance) inside of it that acts as a "jumpbox" for traffic destined to resources held in the VPC's private subnets. Stackery automatically follows AWS best practices when you utilize EC2 (or any AWS tool) and allocates resources into appropriate subnets. More here. In short, Stackery makes those “less scalable” tools scalable for you.
Back to the post!
Brian provided a really succinct and cogent starting place for people with very few users who want to scale: he advocated Amazon Lightsail, which allows you to bundle up compute, storage, and networking as pre-configured application stacks to get up and running in minutes. Once you hit a stride with Lightsail, you can scale up with other resources.
(Another Stackery tie-in that seems shameless but is actually a realization I had as a non-developer during this talk: With Stackery, you get the ease of Amazon Lightsail WHILE being able to do more advanced things and take advantage of more complex tools. lightbulb)
He also recommended folks explore Amazon Aurora serverless: an on-demand, auto-scaling database application designed to provide enterprise-level functionality with open-source pricing (featuring up to 15 read replications and continuous incremental backups to Amazon S3).
Another tip? Start with Amazon SQL -- it’s one of AWS’ oldest tools so it’s established, well-known, and you can find lots of support and documentation around it.
“You aren’t going to break SQL databases with your first millions of users. Really. You won’t.”
When addressing how to actually identify who your users are, Brian joked that nobody ever says “I just signed up for an awesome app! No idea what it does but it has an awesome sign-up experience.” This is just expected of applications nowadays.
Amazon Cognito makes it easy to provide a variety of sign up experiences without necessarily needing to worry about the load generated by the UI _or _how it’s going to scale.
Users >1000
When Brian moved on to the next bracket of users, he brought up a concept that might be common knowledge and old pat in the SaaS realm, but it was novel to me and a sticky idea: Yak shaving. That’s right: taking a straight-blade to a Tibetan ox-like mammal’s hair for a sick fade. Yak shaving: don’t do it! But why?

To break down this metaphor into something that’s actually useful, what Brian was referring to a common pitfall of developers adding unnecessary complexity to an otherwise simple task. For instance: you need to fix a performance issue on a particular page. You start diving deeper and deeper into the issue by reducing the number of packages in use and optimizing the CSS variables so it’s more readable, until someone asks what you are doing and you realize you’re “shaving a yak” and you don’t know why! Don’t do unnecessary Herculean development tasks whose context becomes obtuse quickly. Abstracting away Yak shaving? That’s serverless for ya!
Here, Brian suggested you closely plan your application’s scaling model carefully based on a case-by-case model of horizontal vs vertical scaling.

Scaling is key
Hong Pham took the mic for a great segment on automatic scaling
You want to be able to spin up traffic based on business demand and not have idle provisioned capacity -- aAuto-scaling lets you do this. You can automatically resize compute clusters and, define minimum/maximum pool sizes. Scaling up is the first thing everyone thinks of, you need to make sure your service grows to meet capacity! But scaling down is just as critical if we care at all about costs.
Amazon CloudWatch metrics is the driving indicator that we need scaling: either showing when our services or taxed or when we have idle resources.
Let Stackery make that hard stuff easy
Stackery is an amazing tool to make that hard-to-scale stuff easier to control. It’s primary benefit is making the editing and deployment of serverless stacks much easier with a clean visual editor, VSCode plugin, and environment management. Sign up for a demo today and see how we can accelerate your serverless workflow.
And if you’re posted up in “Lido” reading this on the ground in the hallway, come visit us at booth #724 and hear all about how Stackery can help you scale your user base with AWS serverless best practices-- on one condition: don’t bring a yak!

