How an Under-Provisioned Database 10X'd Our AWS Lambda Costs

This is the story of how running a too small Postgres RDS instance caused a 10X increase in our daily AWS Lambda costs.
It was Valentine's day. I'd spent a good chunk of the week working on an internal business application which I'd built using serverless architecture. This application does several million function invocations per month and stores about 2Gb of data in an RDS Postgres database. This week I'd been working on adding additional data sources which had increased the amount of data stored in Postgres by about 30%.
Shortly after I got into the office on Valentine's day I was alerted that there were problems with this application. Errors on several of the Lambda functions had spiked and I was seeing function timeouts as well. I started digging into Cloudwatch metrics and quickly discovered that my recently added datasources were causing growing pains in my Postgres DB. More specifically it was running out of memory.
You can see the memory pressure clearly in this graph:
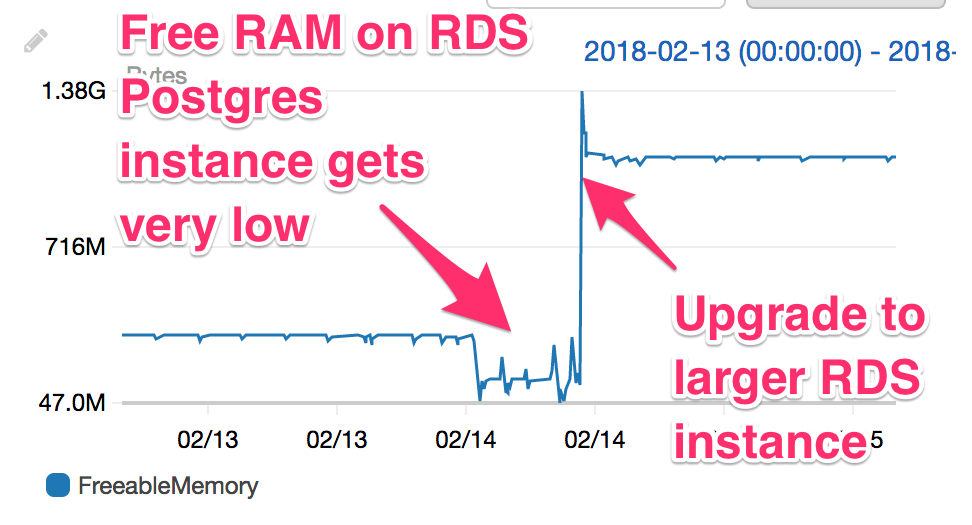
I was able to quickly diagnose that memory pressure within the RDS instance was leading to slow queries, causing function timeouts and errors, which would trigger automatic retries (AWS Lambda automatically retries failed function invocations twice). At some point this hit the DB's connection limits, causing even more errors, a downward spiral. Fortunately I'd designed the microservices within the application to be fault tolerant and resilient to failures, but at the moment the system was limping along and needed intervention to fully recover.
It was clear I needed to increase DB resources so I initiated an upgrade to a larger RDS instance through Stackery's Operations Console. While the upgrade was running I did some more poking around in AWS console.
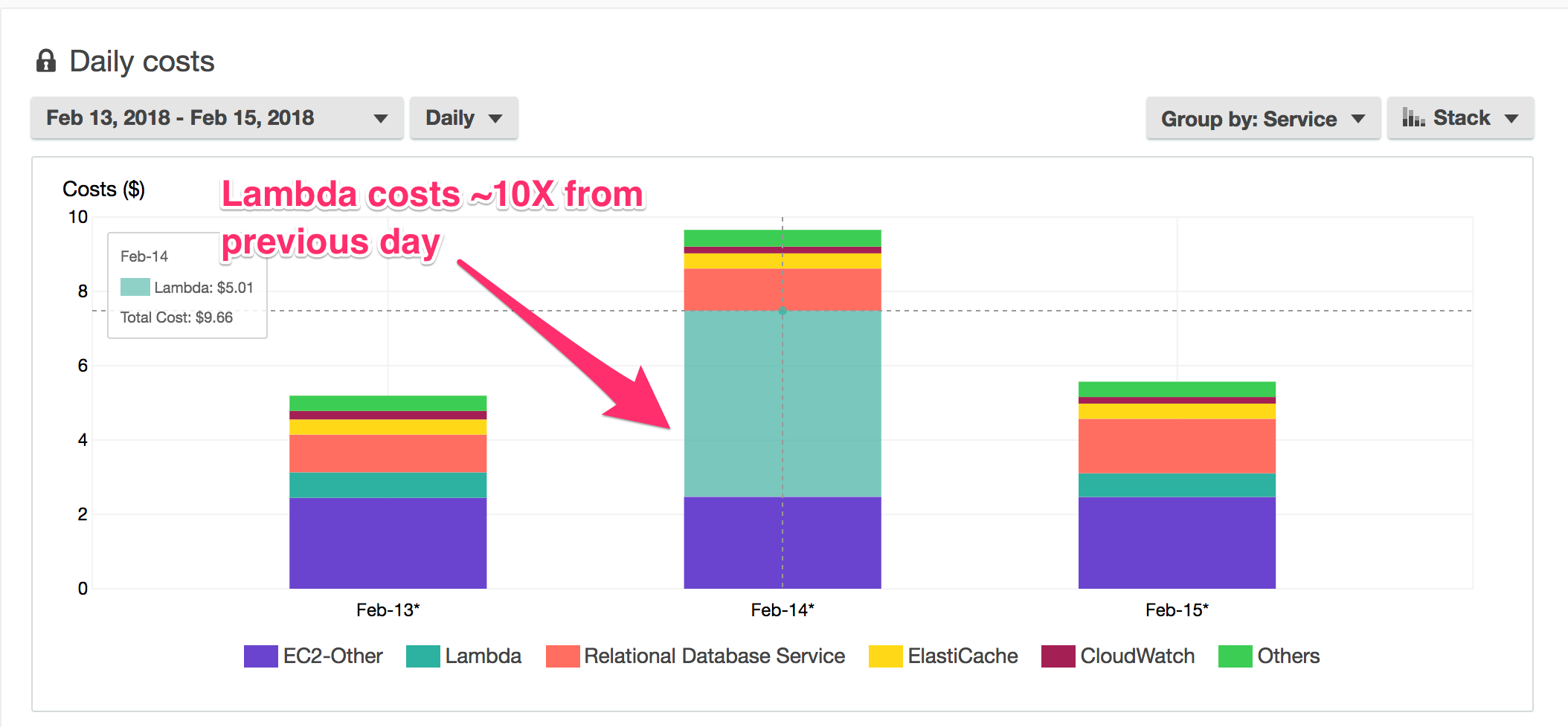
This is when things started to get really interesting. I popped into the AWS Cost Explorer and immediately noticed something strange. My Lambda costs for the application had increase 10X, from about 50¢ the previous day to over $5 on Valentine's Day. What was going on here?
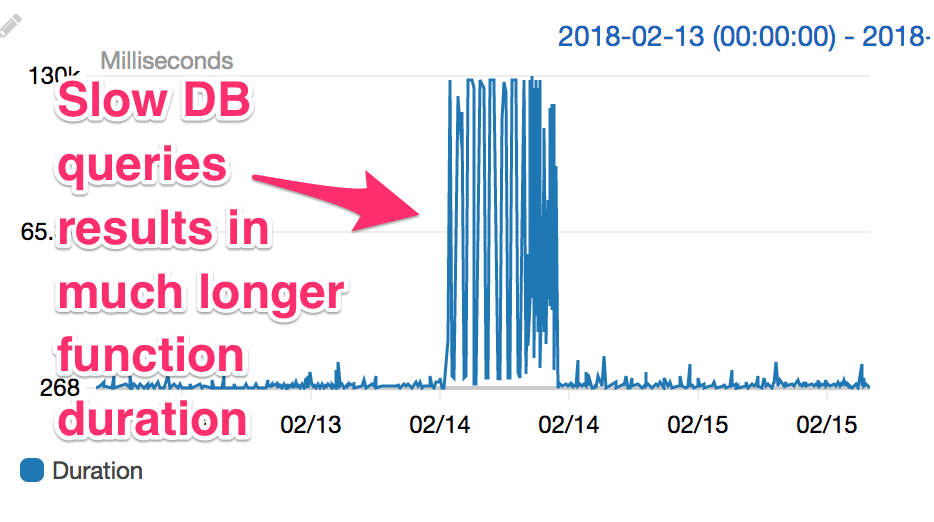
I did some more digging and things started to make sense. Not only had the underprovisioned RDS instance resulted in degraded app performance. It had also increase dramatically increased my average function duration. Functions that ordinarily completed in a few tenths of a second were running up until their timeouts, 30 seconds, or longer in some cases. Because they hit the timeout and failed they'd be retried, which meant even more long function invocations.
You can see the dramatic increase in function runtime clearly in this graph:
Once the RDS instance upgrade had completed things settled down. Error rates dropped and function duration returned to normal. Fortunately the additional $4.50 in Lambda costs won't break the bank either. However this highlights the tighter relationship between cost and performance that exists for serverless architectures. Generally this results in significantly lower hosting costs than traditional architectures, but the serverless world is not without it's gotchas. Fortunately I had excellent monitoring, alerting, and observability in place for the performance, health, and cost of my system, which meant I could quickly detect and resolve the problem before it turned into a full scale outage and a spiking AWS bill.
Related posts