Hands Off Serverless Deployments
How AWS deploys in waves and what to think about when planning your deployments

On day two of #reinvent2020 I watched and tweeted a lot about an awesome talk by @clare_liguori on the AWS Container Services team about hands-off deployments. It's now available to stream on-demand.
Goal of balancing safety and speed is used throughout examples, geared toward microservices but perfectly applicable to server-based deployments. pic.twitter.com/sYekQlYv9R
— Ryan Coleman (@ryanycoleman) December 2, 2020
Clare focused mostly on production deployments, though pre-production CI/CD was covered at the end of the talk. In my view, while the systems may be similar, the goals differ.
Hands-off Deployments in Pre-Production
Before shipping to production, your deployment pipeline should be concerned with:
- Producing sandbox environments of infrastructure to simulate production conditions
- Running unit, integration, and any other relevant test suites that exercise the proposed changes in its sandbox environment
- Validating changes against organizational policies and vulnerability assessments, so that in addition to being functional, changes meet governance and configuration standards set by the team
- Doing all the above as quickly as possible to provide the team with fast feedback cycles and reduce the cost of iterations to address late-stage issues
What’s the point?
Before production changes are deployed, hands-off deployments should be focussed on validating changes in environments that represent production, with the right automation in place to rapidly identify issues that humans can understand and address.
Hands-off Deployments in Production
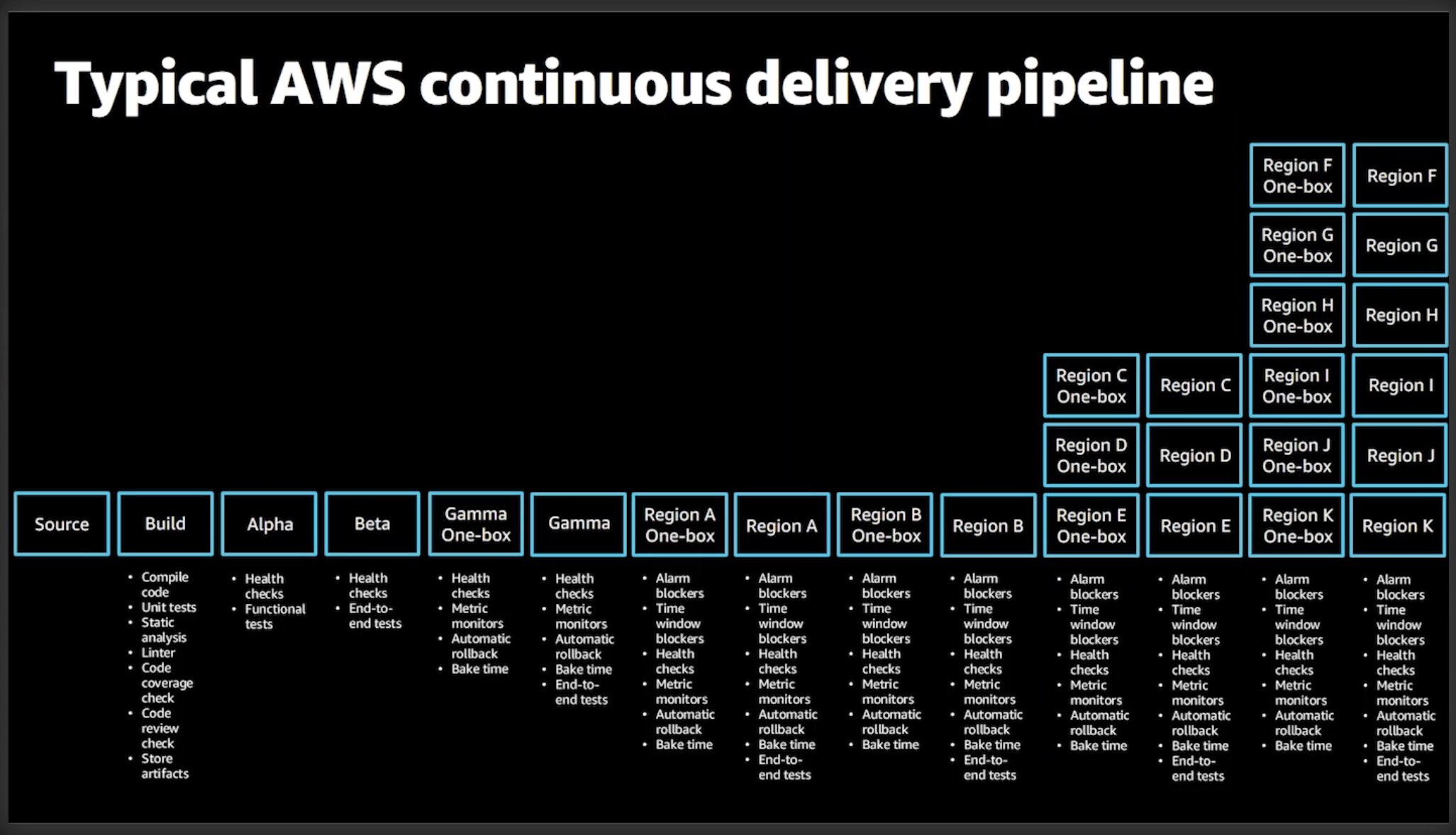
AWS’s “typical” delivery pipeline represents the scale, complexity, and high-stakes of the AWS public cloud. You do not need your hands-off deployment pipeline to be as broad or as deep. Clare's wonderfully illustrated deployment pattern is generally applicable to deployments of varying scope.
Deployment wave strategy seems to be the preferred hybrid, combining a phased versioning rollout with a mix of region/AZs so that you’re going broader with your change the further into the pipeline you get.
— Ryan Coleman (@ryanycoleman) December 2, 2020
Makes sense, but I’m pondering how to express this in CI/CD systems. pic.twitter.com/9jivLIbMXm
Clare called the strategy deployment waves, and it’s a clever approach to the production deployment mindset of balancing safety and speed.

Visualize it by thinking of a series of waves in the ocean.
The waves move toward the shore, which is occupied by customers building their "business sand castles." Each wave represents the latest iteration of code, deployed in sequence. The idea is that you deploy the first wave to a region of the beach where fewer customers are building sand castles.
Once the code is deployed, you use an auto-rollback metrics monitoring strategy to determine whether the change is working nicely for customers. This determines whether a rollback occurs or whether the change proceeds to the second wave of regions.
The second wave goes to a larger region, or perhaps multiple regions, or otherwise represents a larger population of customers that will experience the change being deploying. You continue this process, reinforced by the auto-rollback strategy, until the change is fully deployed everywhere.
Thus, changes can be deployed as soon as they’re ready, where they’ll be gradually exposed to more customer traffic before being reverted or hitting the metaphorical shore.
The idea here is that every change can be rolled back, but it doesn’t have to be global- rollback within the wave/region/az that’s hit an alarm but keep rolling everywhere else. pic.twitter.com/l6pBxK0ePM
— Ryan Coleman (@ryanycoleman) December 2, 2020
It may take a few iterations to achieve the deployment wave strategy, with its metrics-driven auto-rollback machinery, but tooling, like Stackery's CI/CD pipeline can bootstrap you most of the way.
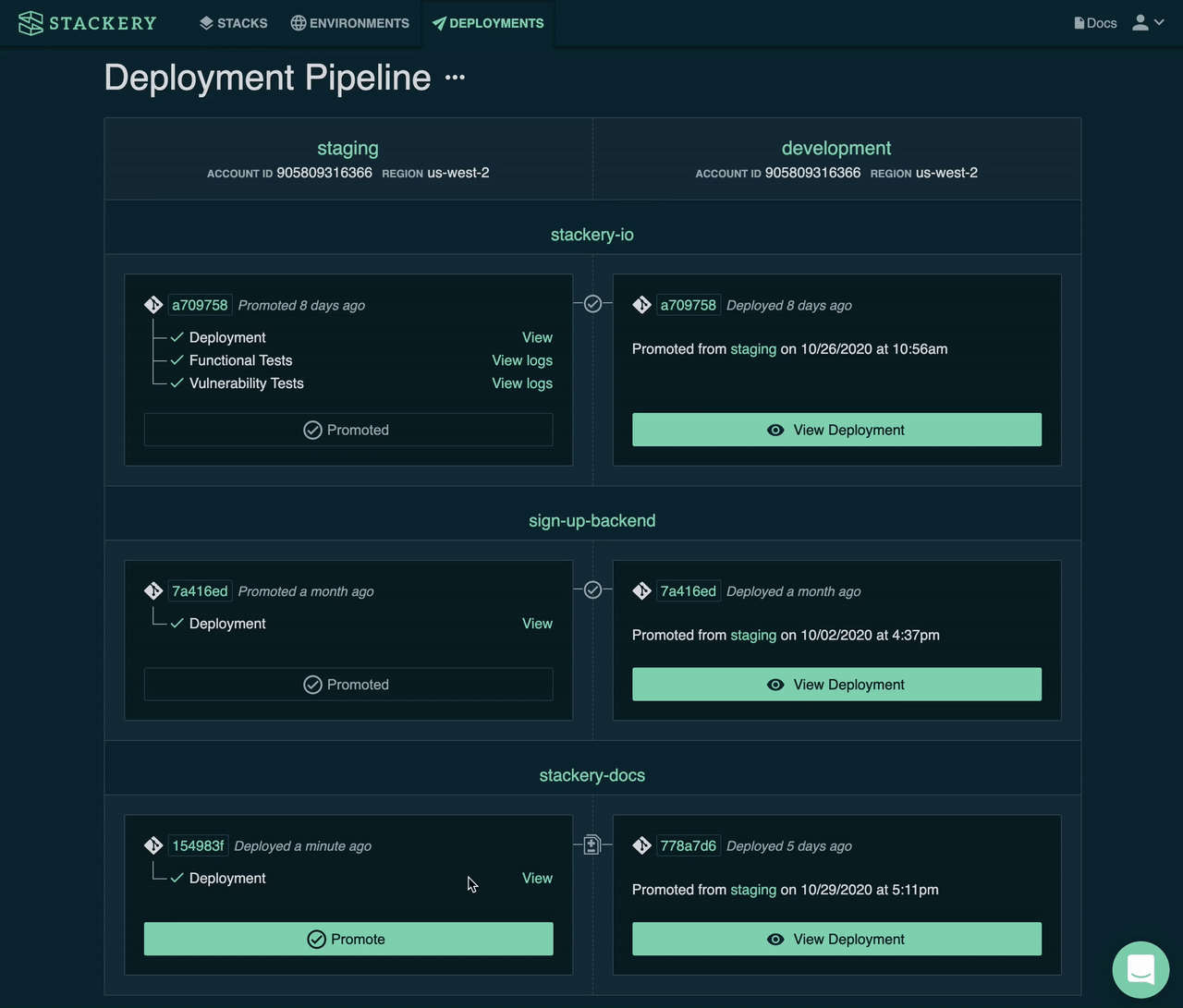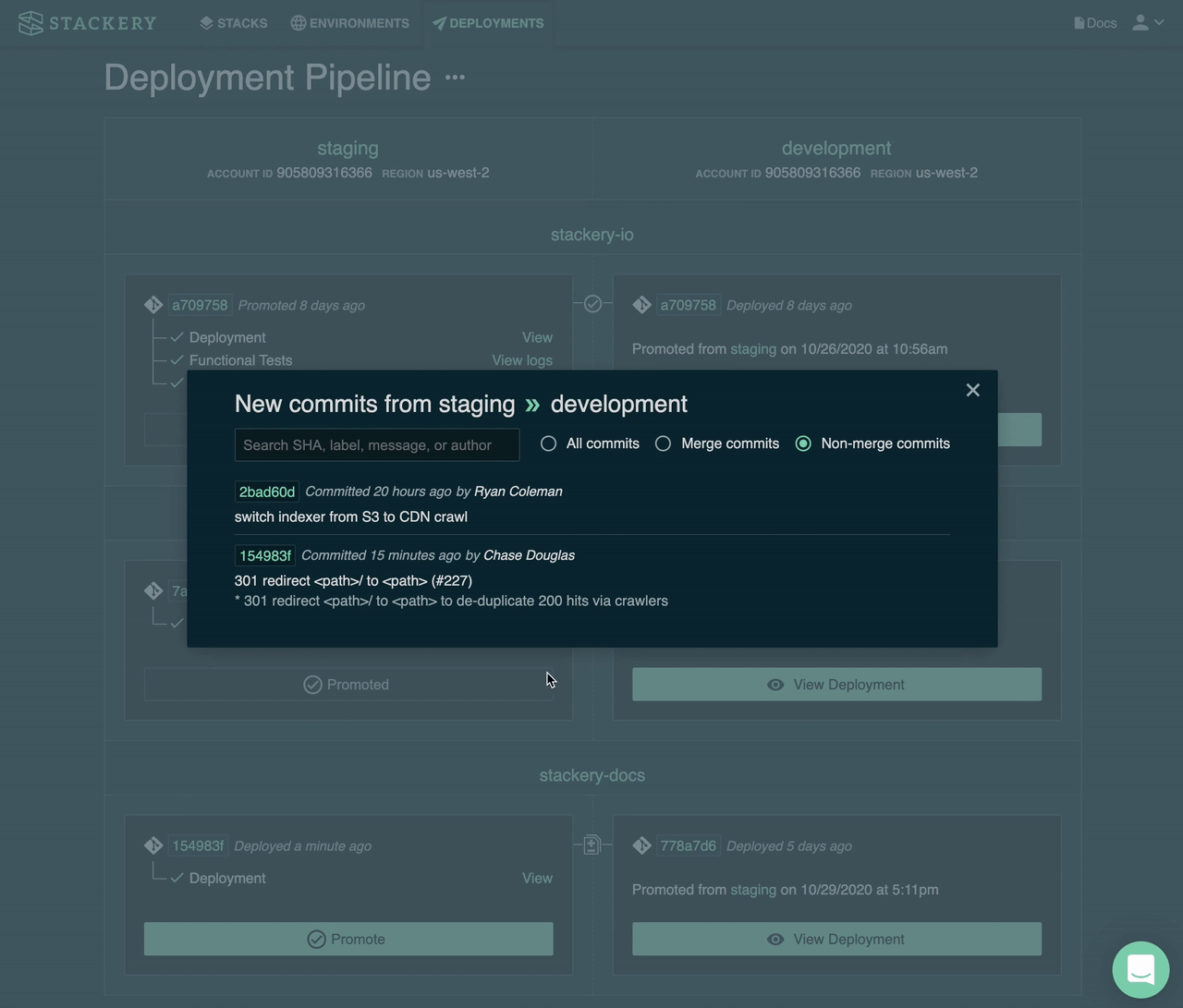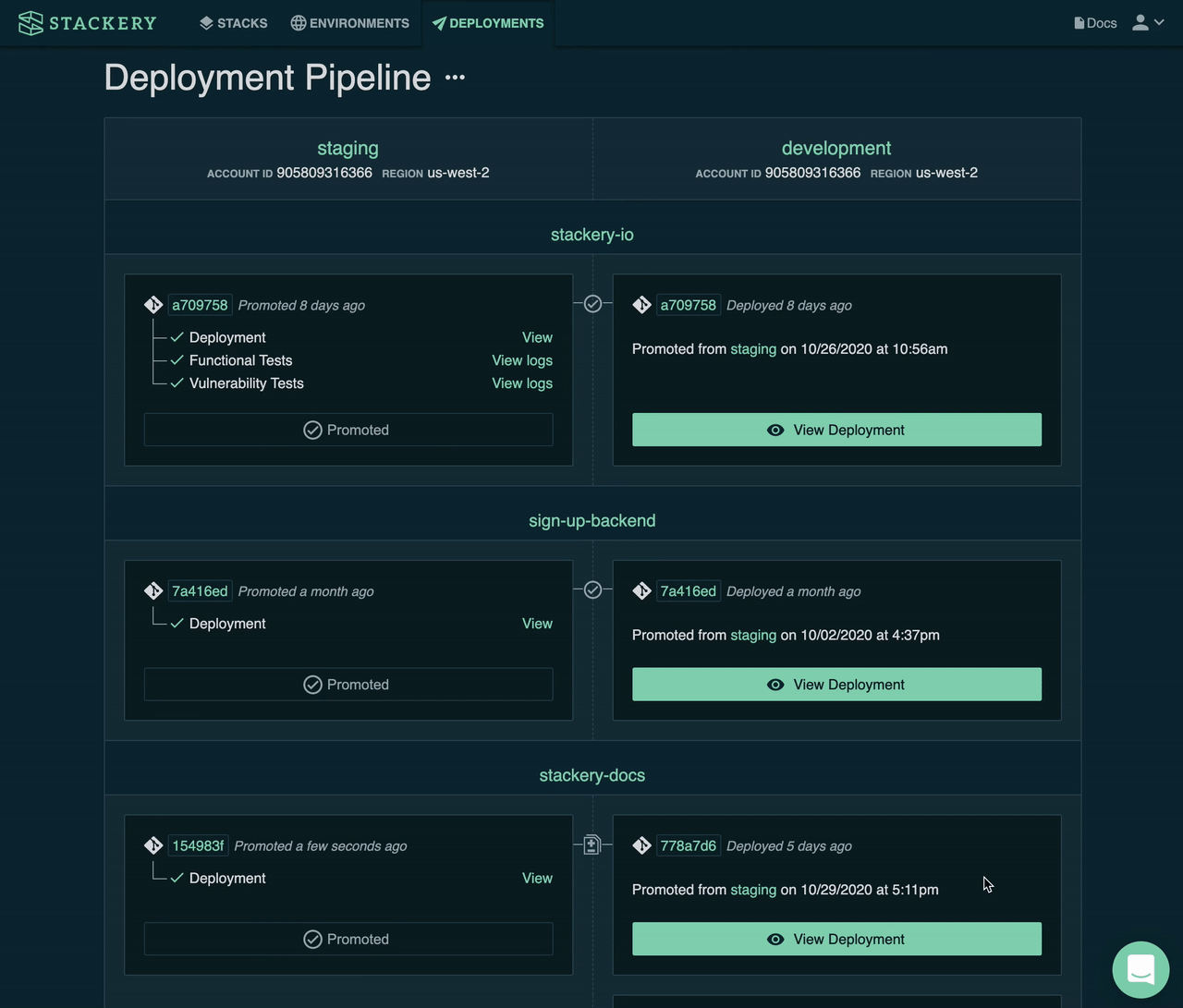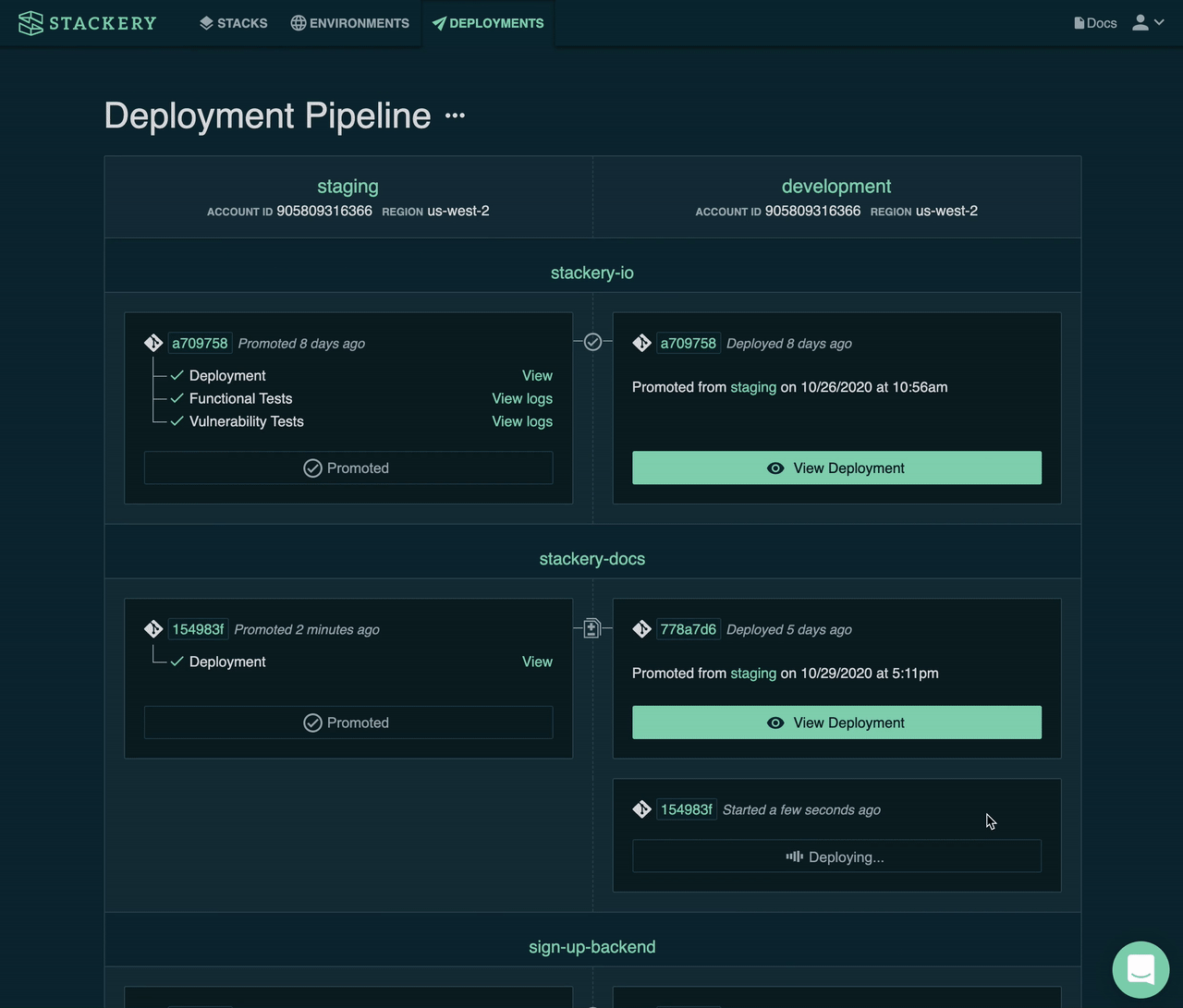
With Stackery, you can get started today with a pipeline that handles pre-production sandbox environment management, test runners and vulnerability assessments, and an auto-promotion pipeline that can similar a wave deployment with 1 AWS region in each wave.
Related posts

What to look for at re:Invent for serverless and DevOps professionals
And how Stackery can help you put it into practice