Error Handling In a Serverless World

 Error handling is tricky. The easiest thing you can do with an error, and some argue the best thing to do, is to let the error do its thing and take your application down with it. There is merit to this approach, especially for unhandled exceptions, because by definition the application is in an unknown state.
Error handling is tricky. The easiest thing you can do with an error, and some argue the best thing to do, is to let the error do its thing and take your application down with it. There is merit to this approach, especially for unhandled exceptions, because by definition the application is in an unknown state.
But errors happen. When they happen, no matter how we handle the error in the moment, we need to learn from them to ensure the error does not happen again. We need a way to report the errors to developers who can fix them.
Error Aggregating Services
There are products that provide libraries to catch uncaught exceptions and report them to back to an error aggregating service. One example is the New Relic Browser product, which I had the fortune of being the technical lead for from concept to GA. New Relic Browser was extra helpful in that it not only caught and reported exceptions occurring within browsers, it was also good at correlating errors across browser vendors and versions. As a developer, you then had a wealth of knowledge to help you determine which errors were occurring most frequently and how to fix them.
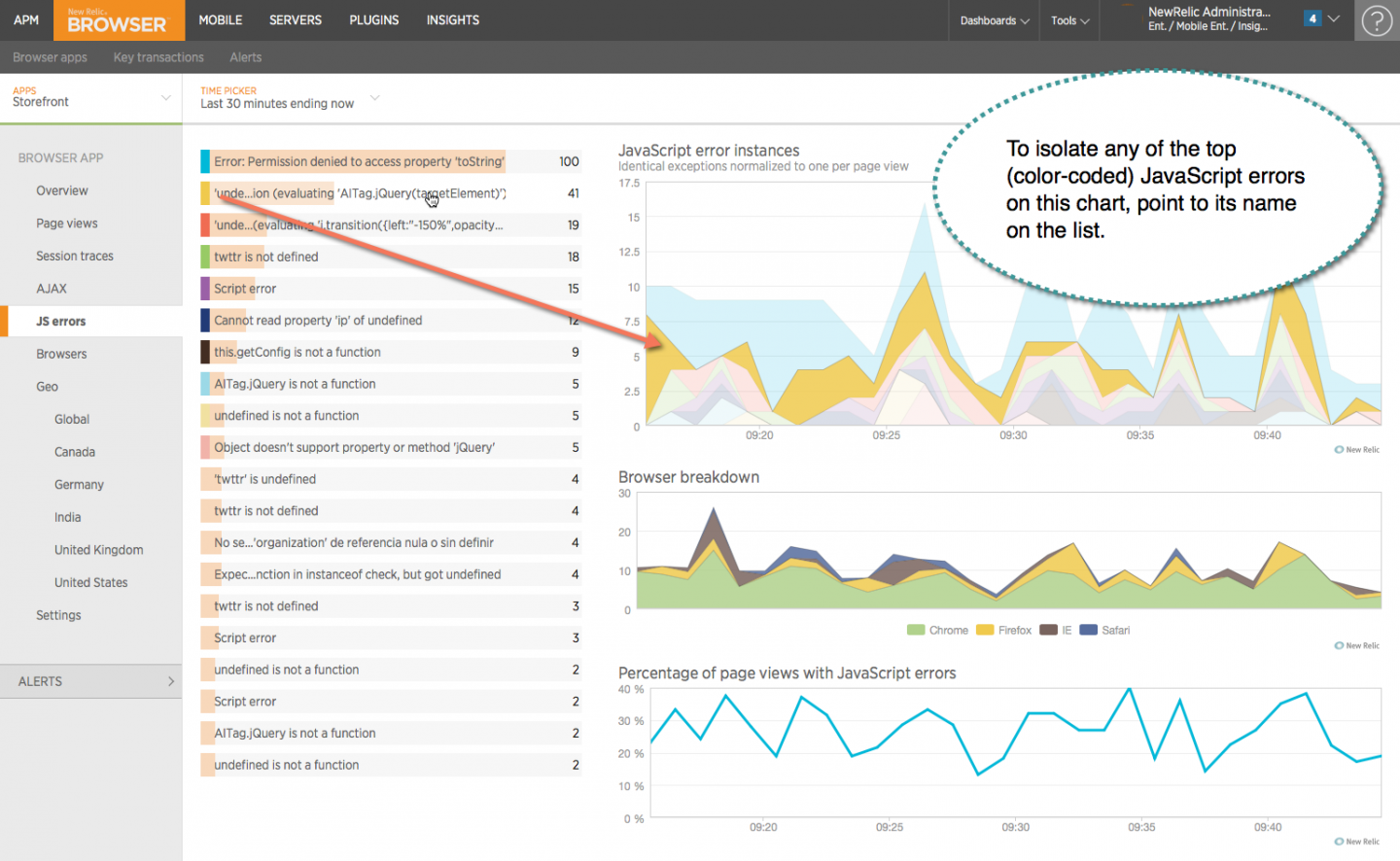
The Challenge Of Serverless Error Reporting
Error aggregating services provide a ton of value to developers. But serverless functions present a challenge. Almost all error aggregating services will catch errors and queue them up to be reported periodically. For example, the New Relic Application Monitoring agents batch errors and report them once per minute. In contrast, many serverless functions are written to fail when an error occurs, never to be run again because a fresh function instance can take its place. Delaying the reporting of errors would prevent the errors from ever being reported at all.
Stackery To The Rescue!
At Stackery, we recognize the importance of proper error handling. There must be a way to aggregate errors from serverless functions, and hopefully in a way that allows for flexible handling of error instances. This is why we built the Errors node. As functions run, all error conditions, including timeouts, are captured by Stackery. When an error occurs due to a synchronous invocation from another function, the erring function will respond with a proper Error object. Further, if an Errors node exists in the stack, all errors will be emitted from the Errors node.
One powerful use case for the Errors node is to send errors to an error aggregating service, like Rollbar. These errors can then be analyzed to determine how to resolve them.

At Stackery we are always working to help our customers build better apps. We hope our error handling features help you reduce mean time to resolution for issues in your apps. Stay tuned for even easier integrations with error aggregating services in the near future!
Related posts