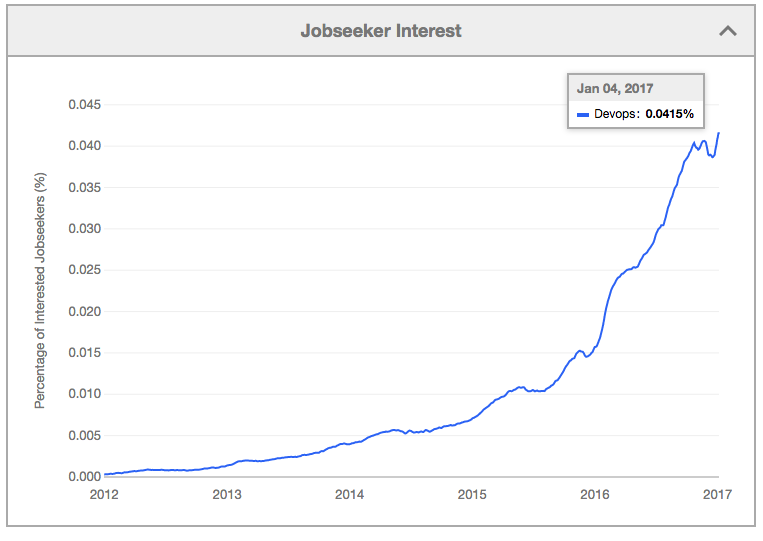
Bringing Shadow IT into the Fold

 Satya Nadella, CEO of Microsoft, says that "every business will become a software business." Indeed, it's not a stretch to see how software is enabling businesses, across the full spectrum of industries, to innovate faster and create new value for their customers and shareholders. What may be less readily apparent is that even within these organizations, more and more teams are embracing software-enabled transformation of their methods and processes, well beyond the traditionally product-driven IT group. This phenomena of departments as varied as finance, marketing, R&D, and business intelligence embracing software to accelerate their organizational value is what we refer to as "Shadow IT."
Satya Nadella, CEO of Microsoft, says that "every business will become a software business." Indeed, it's not a stretch to see how software is enabling businesses, across the full spectrum of industries, to innovate faster and create new value for their customers and shareholders. What may be less readily apparent is that even within these organizations, more and more teams are embracing software-enabled transformation of their methods and processes, well beyond the traditionally product-driven IT group. This phenomena of departments as varied as finance, marketing, R&D, and business intelligence embracing software to accelerate their organizational value is what we refer to as "Shadow IT."
Shadow IT can be seen in marketing teams spinning up applications to deliver content. It can be seen in finance pulling data out of production data stores for better forecasting. It's apparent in product spin-out groups, like R&D teams, quickly iterating with software and the underlying infrastructure it runs on. Put simply, Shadow IT is uncoordinated IT efforts throughout your organization and organizations just like yours.
The Costs of Shadow IT
The costs of Shadow IT are two-fold. First, and most obviously, traditional, product-driven IT teams are often serving as the gatekeepers to data and access to production-tier infrastructure. This weighs as a cost on the IT department, slowing productivity and development with interrupt-driven work that frequently leads to duplication of effort and delays across the organization. While the product impacts are fairly straight-forward, the more subtle costs accumulate as Shadow IT teams are hampered with accessing the company's own systems and information.
The second, more insidious, cost is realized with the heterogeneity of the systems created by each of these teams to accomplish their missions. When marketing introduces new customer datastores outside of the product systems, for example, they create not only redundant storage costs (which may be trivial), but more importantly, they create uncoordinated systems which lack data fidelity and create multiple, inconsistent places of record for this data. Which data is more true, Marketing's or Product's? Who has an accurate customer count, Finance or Sales? This fragmentation of knowledge slows decision-making across the organization and leads to inconsistent views by varied decision-makers.
Bringing Shadow IT into the Fold
These problems can be abated with an intentional view of acknowledging the need for IT enabled teams throughout the organization. It starts by viewing these teams, not as renegade engineers, but as core constituents served by your IT group.
To begin, planned and coordinated self-serve access to data and infrastructure can go a long way to alleviate the interrupt-driven nature of this work. Many companies implement access to read-only replicas of master data stores, enabling access to internal users without jeopardizing stability of core systems or risking customer-impacting system disruptions. Creating dedicated infrastructure resources for these teams, patterned after (but not identical to) production systems, is another approach for improving access to these systems.
The secondary advantage to this approach comes from systems homogeneity. When a centralized IT group manages consistent and reliable access to production-worthy systems, they can also maintain a true source-of-record for data and reduce the number of inconsistent technologies and licenses being consumed across the organization. This simplicity makes many tasks easier, not least of which is enabling engineers to move fluidly between systems with predictable access to resources.
Life in the Fold
These changes bring dramatic improvements, not just to the IT organization, but to the company as a whole. As all teams experience true IT enablement, coordination among complimentary tasks, like decision-making, become dramatically accelerated. This win-win outcome is achievable as we bring Shadow IT back into the fold.
Related posts