The Lazy Programmer’s Guide to Web Scrapers


I am a proud lazy programmer. This means that if I can automate a task, I will absolutely do it. Especially if it means I can avoid doing the same thing more than once. Luckily, as an engineer, my laziness is an asset - because this week, it led me to write an HTML scraper for our Changelog, just so I wouldn't have to manually update the Changelog feed on our new app homepage (btw, have you seen our new app homepage? It's pretty sweet).

If only I could also make robots mow my lawn...
Why automation?
I am a firm believer in lazy programming. That doesn't mean programming from the couch in your PJs (though that's what work from home days are for, amirite?). I mean working smarter rather than harder, and finding ways to automate repeated processes.
One of our more recent processes was adding a Changelog to our Docs page, to let our users know what's going on with Stackery and so we can announce major updates. However, the initial Changelog update process was anything but lazy:
- Create a Changelog doc
- Yell at engineers for not updating it*
Yup, room for improvement.
A better way of doing things
After much thought and some trial and error, we came up with a better system. Here's what our new Changelog process looks like, in a nutshell:
- Each engineer updates an internal Changelog file in an individual repo as part of the PR process
- When the PR is merged, a scraper Lambda function is triggered by a Git webhook and compiles the new Changelog item into a single doc
- That doc is then reviewed a few times a week and the most interesting items are written up in our public Changelog (this is the unavoidably manual part of the process, until we build an AI that writes puns, anyway)
- The public Changelog is scraped by our changelog scraper Lambda and its four most recent items are pulled, reformatted, and displayed on the app homepage
Here's the scraper function I built that does the last part of the process:
const AWS = require('aws-sdk');
const cheerio = require('cheerio');
const rp = require('request-promise');
const changelogUrl = 'https://docs.stackery.io/en/changelog/';
const s3 = new AWS.S3();
exports.handler = async () => {
// options for cheerio and request-promise
const options = {
uri: changelogUrl,
transform: function (html) {
return cheerio.load(html, {
normalizeWhitespace: true,
xmlMode: true
});
}
};
// remove emojis as they don't show up in the output HTML :(
function removeEmojis (string) {
const regex = /(?:[\u2700-\u27bf]|(?:\ud83c[\udde6-\uddff]){2}|[\ud800-\udbff][\udc00-\udfff]|[\u0023-\u0039]\ufe0f?\u20e3|\u3299|\u3297|\u303d|\u3030|\u24c2|\ud83c[\udd70-\udd71]|\ud83c[\udd7e-\udd7f]|\ud83c\udd8e|\ud83c[\udd91-\udd9a]|\ud83c[\udde6-\uddff]|[\ud83c[\ude01\uddff]|\ud83c[\ude01-\ude02]|\ud83c\ude1a|\ud83c\ude2f|[\ud83c[\ude32\ude02]|\ud83c\ude1a|\ud83c\ude2f|\ud83c[\ude32-\ude3a]|[\ud83c[\ude50\ude3a]|\ud83c[\ude50-\ude51]|\u203c|\u2049|[\u25aa-\u25ab]|\u25b6|\u25c0|[\u25fb-\u25fe]|\u00a9|\u00ae|\u2122|\u2139|\ud83c\udc04|[\u2600-\u26FF]|\u2b05|\u2b06|\u2b07|\u2b1b|\u2b1c|\u2b50|\u2b55|\u231a|\u231b|\u2328|\u23cf|[\u23e9-\u23f3]|[\u23f8-\u23fa]|\ud83c\udccf|\u2934|\u2935|[\u2190-\u21ff])/g;
return string.replace(regex, '');
}
// parse the scraped HTML, then make arrays from the scraped data
const makeArrays = ($) => {
const titleArray = [];
const linkArray = [];
$('div > .item > h2').each(function(i, elem) {
titleArray[i] = removeEmojis($(this).text());
});
$('div > .item > .anchor').each(function(i, elem) {
linkArray[i] = $(this).attr('id');
});
return makeOutputHtml(titleArray, linkArray);
}
// format the arrays into the output HTML we need
const makeOutputHtml = (titleArray, linkArray) => {
let output = `<h2>Stackery Changelog</h2>
<p>We're always cranking out improvements, which you can read about in the <a href='https://docs.stackery.io/en/changelog/' target='_blank' rel='noopener noreferrer'>Stackery Changelog</a>.</p>
<p>Check out some recent wins:</p>
<ul>
`;
for (let [i, title] of titleArray.entries()) {
// only get the latest four entries
if (i < 4) {
output += `<li><a href='https://docs.stackery.io/en/changelog/#${linkArray[i]}' target='_blank' rel='noopener noreferrer'>${title}</a></li>
`;
}
}
output += `</ul>`;
return output;
};
// request the changelog HTML
const response = rp(options)
.then( async ($) => {
// create output HTML
const outputHtml = makeArrays($);
// set the bucket parameters
const params = {
ACL: 'public-read', // permissions of bucket
Body: outputHtml, // data being written to bucket
Bucket: process.env.BUCKET_NAME, // name of bucket in S3 - BUCKET_NAME comes from env vars
Key: 'changelog/changelog.html' // path to the object you're looking for in S3 (new or existing)
};
// put the output HTML in a bucket
try {
const s3Response = await s3.putObject(params).promise();
// if the file is uploaded successfully, log the response
console.log('Great success!', s3Response);
} catch (err) {
// log the error if the file is not uploaded
console.log(err);
const message = `Error writing object ${params.Key} to bucket ${params.Bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
} finally {
// build an HTTP response
const res = {
statusCode: 200,
headers: {
'Content-Type': 'text/html'
},
body: outputHtml
};
return res;
}
})
.catch((err) => {
console.log(err);
});
return response;
};
Of course, any lazy serverless developer will use Stackery to avoid the tedium of writing their own YAML and configuring permissions, so naturally, I built this scraper in our app:
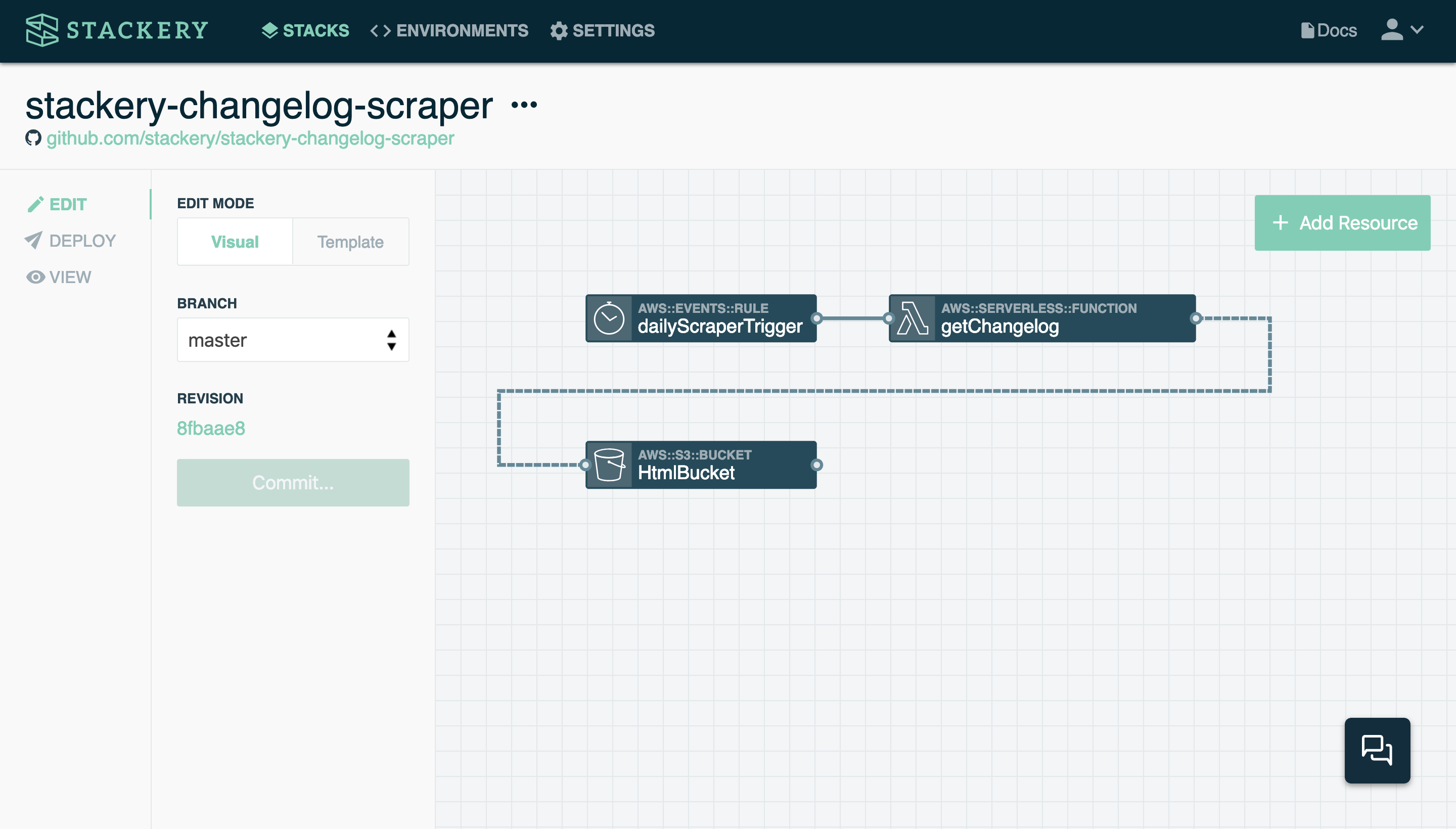
It includes three cloud resources:
- A Timer (AWS CloudWatch schedule event) that triggers the scraper function once a day
- A Lambda function that pulls HTML content from our public Changelog, trims the data to just titles and links, outputs to a new HTML file and puts it in the designated S3 bucket
- An S3 bucket that holds our HTML file, which is fetched by the app and displayed on the homepage
If you'd like to implement your own web scraper that outputs to an S3 bucket, grab the code from our GitHub repository - after all, the best lazy programmers start with others' code!
* Just kidding. There's no yelling at Stackery, only hugs.
Related posts

